1 GPU+several lines of code, big model training speed up 40%!Seamless support huggingface
Author:Quantum Time:2022.07.13
Mingmin is from the quantity of the Temple of Temple | Public Account QBITAI
I have to say that in order to allow more people to use big models, the technical circle is really surprising!
Is the model not open enough? Someone gets a free open source version by themselves.
For example, Dall Emini, which has recently been popular on the whole network, OPT-175B (Open Pretrained Transformer) open by Meta.
Through the re -engraving method, the big model that was not available for Open became available to everyone.

Some people think that the model is too large, and it is difficult for individual players to bear the cost of sky -high price.
Therefore, heterogeneous memory, parallel calculation and other methods are proposed to accelerate the large model training and reduce costs.
For example, the COLOSSAL-AI of the open source project has just achieved a big model of the 18 billion parameters of the 18 billion parameters of the Nvidi 3090 not long ago.

In these two days, they came to a new wave:
Seamlessly supports the Hugging Face community model. Just add a few lines of code to achieve low -cost training and fine -tuning of large models.

You know, as one of the most popular AI libraries at the moment, Hugging Face provides more than 50,000 AI models, which is the first choice for many AI players to train big models.
The COLOSSAL-AI operation is to make the training fine-tuning of the open model more practical.
And also improved in training effects.
On a single GPU, compared to Microsoft's DeepSpeed, the automatic optimization strategy of Colossal-AI can achieve a 40%acceleration as soon as possible.
The traditional deep learning framework such as PyTorch can no longer run such a large model on a single GPU.
For parallel training using 8 GPUs, you can only add -NProcs 8 to the startup command.
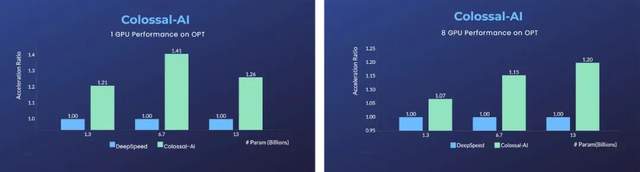
After this wave, it can be said that the cost, efficiency, and practical problems that personal AI players need to consider are all grasped ~
No need to modify the code logic
Just say you don't practice a fake handle.
Let ’s take OPT as an example. Let’ s take a look at how the new features of Colossal-AI are used.
OPT, all known as Open Pretrained Transformer.
It is published by Meta AI and the maximum number of parameters of the benchmarking GPT-3 can reach 175 billion.
The biggest feature is that the GPT-3 does not open the model weight, while OPT opens all code and weight.
Therefore, every developer can develop personalized downstream tasks on this basis.
The following example is the fine -tuning of causal language models based on the pre -training weight provided by OPT.
Mainly divided into two steps:
The first step is to add the configuration file to run, which is to add configuration files based on the task you want.
For example, on a GPU, taking heterogeneous training as an example, you only need to add relevant configuration items to the configuration file, and you do not need to change the training logic of the code.
For example, tensor_placement_policy determines the strategy of heterogeneous training, and the parameters can be CUDA, CPU and Auto.
The advantages and adaptation of each strategy are different.
CUDA: Place all model parameters on the GPU, which is suitable for traditional scenes that can still be trained when not offload.
CPU: Place the model parameters in the CPU memory, and only retain the current weight of the current calculation in the GPU video memory, which is suitable for the training of oversized models.
Auto: According to real-time memory information, the number of parameters retained in GPU video memory can be automatically decided to maximize the use of GPU video memory and reduce data transmission between CPU-GPU.
For ordinary users, using Auto strategy is the most convenient.
In this way, the best heterogeneous strategy can be selected by Colossal-AI to automatically dynamically dynamically dynamically dynamically.
from colossalai.zero.shard_utils import TensorShardStrategyzero = dict(model_config=dict(shard_strategy=TensorShardStrategy(), tensor_placement_policy="auto"), optimizer_config=dict(gpu_margin_mem_ratio=0.8))第二步,是在配置文件准备好后,插入Several lines of code to start new features.
First, use the configuration file to start the colossal-ai through a line of code.
Colossal-AI will automatically initialize the distributed environment, read the relevant configuration, and then automatically inject the function in the configuration into the model and optimizer component.
colossalai.launch_from_Torch (config = './Configs/Colossalai_zero.py') then, still defines data sets, models, optimizers, loss functions, etc. as usual. For example, using the native PyTorch code directly, when defining the model, you only need to place the model at the initialization of ZeroinitContext.
Here, the OptForcausallm model and pre -training weight provided by Hugging Face are fine -tuned on the Wikitext dataset.
with ZeroInitContext(target_device=torch.cuda.current_device(), shard_strategy=shard_strategy, shard_param=True): model = OPTForCausalLM.from_pretrained( 'facebook/opt-1.3b' config=config )接下来,只需要调用colossalai.initialize, You can uniformly inject the heterogeneous memory function defined in the configuration file into the training engine to start the corresponding function.
engine, train_dataloader, eval_dataloader, lr_scheduler = colossalai.initialize(model=model, optimizer=optimizer, criterion=criterion, train_dataloader=train_dataloader, test_dataloader=eval_dataloader, lr_scheduler=lr_scheduler)还是得靠GPU+CPU异构
The key to allowing users to achieve the "fool -style" operation as the above is that the AI system itself is smart enough.
The core role is Gemini, an efficient heterogeneous memory management subsystem of the Colossal-AI system.
It is like a general manager in the system. After collecting the information required for calculation, it dynamically allocates the memory of the CPU and GPUs.
The specific working principle is to warm up in the previous STEP and collect the memory consumption information in the PyTorch dynamic calculation diagram.
After the preheating, before calculating an operator, using the collected memory use records, Gemini will reserve the peak memory required by this operator on the calculating device, and move some models from the GPU video memory to the CPU memory at the same time to the CPU memory Essence
Gemini's built -in memory manager marks a status information for each amount, including HOLD, Compute, Free, etc.
Then, according to the dynamic query memory usage, continuously dynamically convey the states and adjust the amount of tensor.
The direct benefit of bringing is to maximize the model capacity and balance training speed when the hardware is very limited.
You know, the mainstream method of the industry Zero (Zero Reduense Optimizer), although the method of using the CPU+GPU heterogeneous memory, is still a static division, which will still cause problems such as system collapse and unnecessary communication.
Moreover, the method of using dynamic heterogeneous CPU+GPU memory can also use the method of add memory to expand memory.
It is more cost -effective than buying high -end graphics cards.
At present, using Colossal-AI methods, RTX 2060 6GB ordinary game instinct training 1. 1.5 billion parameter model; RTX 3090 24GB host directly single-out 18 billion parameters; Tesla V100 32GB can be won by 24 billion parameters. In addition to maximizing memory, Colossal-AI also uses a distributed parallel method to continuously improve the training speed.

It proposes complex parallel strategies such as parallel, parallel flowing, and 2.5 dimension of data at the same time.
Although the method is complicated, it is still very "fool operation". It only needs to be briefly declared to achieve automatically.
No need to invade code like other systems and frameworks, manually process complex underlying logic.
Parallel = Dict (pipeline = 2, tensor = dict (mode = '2.5d', depth = 1, size = 4)) What else can Colossal-AI do?
In fact, since the open source, Colossal-AI has many times in Github and PaPers with Code, ranking first in the world, and it is famous in the technical circle.
In addition to the above-mentioned single GPU training models, the Colossal-AI expands to dozens of or even hundreds of GPU large-scale parallel scenes, compared with the existing systems such as Nvida Megatron-LM, performance can be turned over throughout the performance. Double, the use of resources can be reduced to one -tenth.
Council, in terms of pre-training GPT-3 oversized AI models, the cost saved can reach millions of yuan.
According to reports, the COLOSSAL-AI-related solutions have been used by well-known manufacturers in industries such as autonomous driving, cloud computing, retail, medicine, and chips.
At the same time, they also pay great attention to the construction of open source communities, provide Chinese tutorials and open user community forums, and continuously update iteration according to everyone's needs feedback.

For example, we found that there have been fans left a message to ask, can the Colossal-AI load some models on the Hugging Face directly?
Well, this update is here.
So, for big model training, what difficulties do you think there are urgent solutions now?
Welcome to leave a message to discuss ~

Portal
Project address: https://github.com/hpcaitech/colossalai
Reference link: [1] https://medium.com/@yangyou_berkeley/colossal-- seamlessly-Accelerates-models-Aow-Costs-face-4d1a887e500D [2] https: // acttexI // A .org/abs/2202.05924v2 [3] https://arxiv.org/abs/2205.11487 [4] https://github.com/features/copilot [5] https://github.com/huggingFace/transFormerss
- END -
Multi -departments in Huidong County, Liangshan Prefecture jointly went to towns to carry out anti -drug propaganda activities

In order to give full play to the role of the member units of the Forbidden Drug C...
Early Asset Road | Huawei Payment of 100 million monthly active households; Jingdong Group completes the compulsory acquisition of Chinese logistics assets

Huawei pays 100 million monthly living householdsNews on July 14, Huawei has paid ...