Active Learning Overview, Strategy and Uncertainty
Author:Data School Thu Time:2022.07.08

Source: Deephub IMBA
This article is about 2400 words, it is recommended to read for 9 minutes
Active learning is a direction to solve the problem of labeling data, and it is a very good direction.
Active learning refers to the process of priority sorting the data that needs to be tagged, so as to determine which data can have the greatest impact on the training supervision model.
Active learning is a strategy of learning algorithm that can interact with the user (Teacher or Oracle) and mark new data points with real tags. The process of active learning is also called optimized experimental design.
The motivation for active learning is that it is equivalent to not all samples labeled.
Active learning can greatly reduce the amount of marking data required for the training model through the priority sorting of experts' markers. Reduce costs while improving accuracy.
Active learning is a strategy/algorithm, which is an enhancement of existing models. Not a new model architecture.
Actively learning is easy to understand and is not easy to execute.
The key idea behind the active learning is that if the machine learning algorithm is allowed to select the data it learns, so that you can use less training labels to achieve higher accuracy. ——Active leading liticture Survey, Burr Settles
Active learning profile
Active learning is not to collect all the labels for all data, but to sort the most difficult data to understand the model, and only label the label on those data requirements. Then the model is trained for a small amount of data that has been marked. After the training is completed, it is required to label the most uncertain data again.
By prioritizing the uncertain sample, the model can allow experts (artificial) to concentrate with the most useful information. This helps the model to learn faster and let the experts skip data that does not help the model much. In some cases, the number of labels collected from experts can be greatly reduced, and a good model can still be obtained. This can save time and money for machine learning projects!
Active learning strategy
There are many papers that introduce a variety of methods to determine the data points and how to iterate on the method. The most common and direct way in this article will be introduced, because this is the simplest and easiest understanding.
Use active learning steps on the unbar data set::
The first thing to do is to manually mark a very small sub -sample.
Once there are a small amount of marking data, you need to train it. Of course, this model will not be great, but it will help us understand which areas that need the first mark of the parameter space.
After the training model, the model is used to predict the category of each remaining unblocked data point.
According to the prediction of the model, select the score on each unbar data point (in the next section, you will introduce some of the most commonly used scores)
Once you select the best way to prioritize labels, ite and repetition can be used for this process: new models are trained on the new label data set based on priority scores. Once the new model is trained on the data set, the data points that are not marked can run and update the priority score in the model, and continue to mark.
In this way, as the model becomes better and better, we can continuously optimize the label strategy.
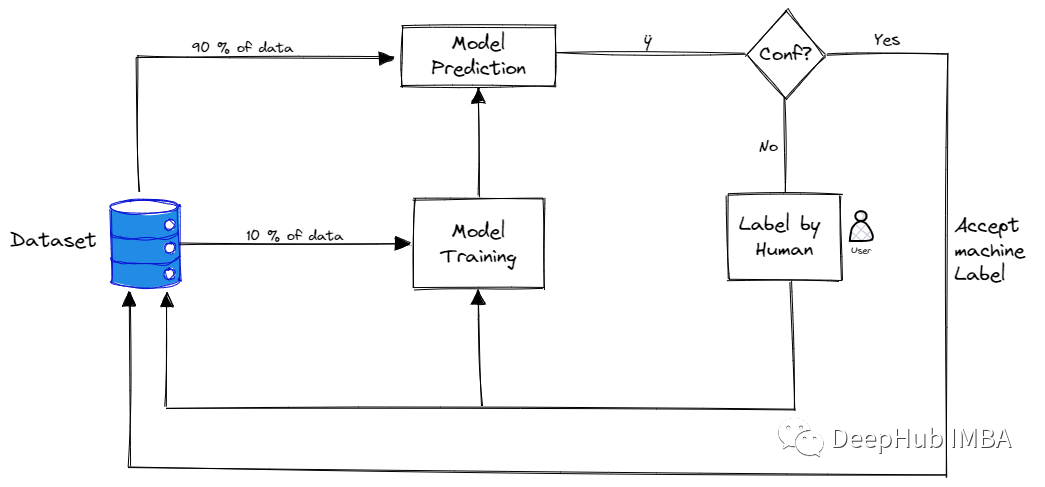
Active learning method based on data stream
In the flow -based active learning, the collection of all training samples is presented to the algorithm in the form of flow. Each sample is sent to the algorithm separately. The algorithm must immediately decide whether to mark this example. The training sample selected from this pool is marked by Oracle (artificial industry expert). Before displaying the next sample, the mark is immediately accepted by the algorithm.
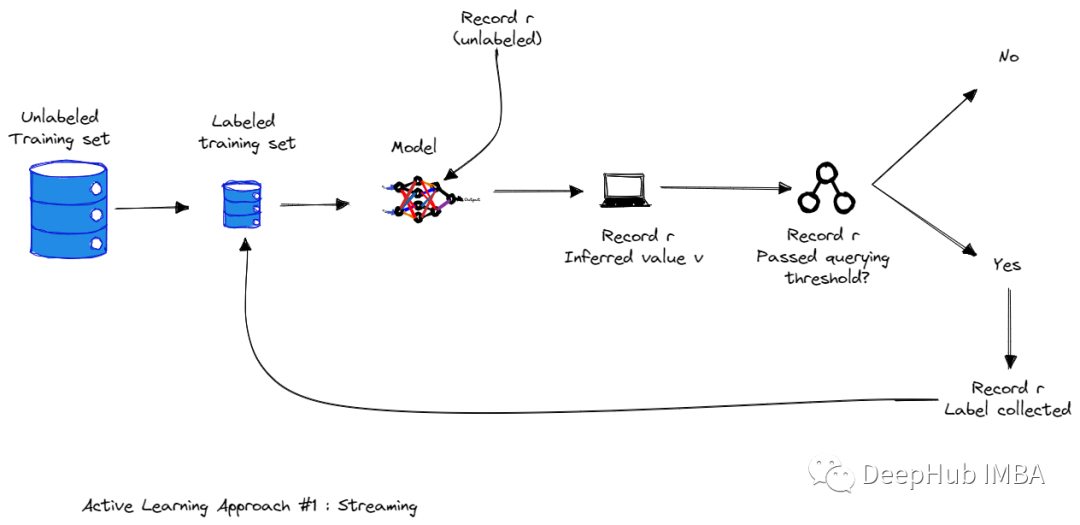
Active learning method based on data pool
In the sampling of the pool, the training sample is selected from a large unsigned data pool. The training sample selected from this pool is marked by Oracle.
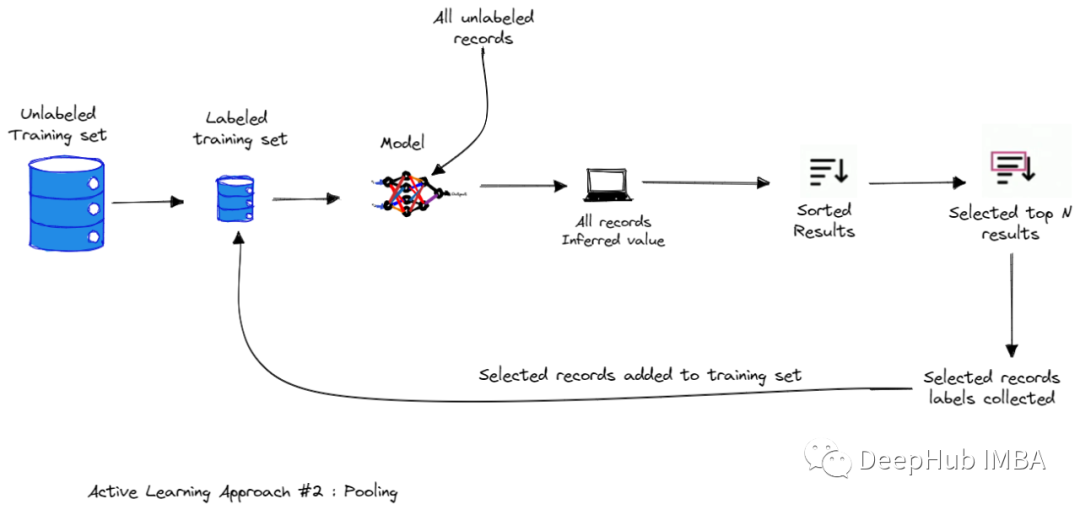
Active learning method based on query
This method based on committee inquiry uses multiple models instead of a model.
Query By Committee, which maintains a model collection (collection is called committee), selects the most "controversial" data point through query (voting) as the next data point that needs to be marked. Through this committee's model to overcome the restricted assumptions that a single model can express (and we don't know what assumptions should be used at the beginning of the mission).
Uncertainty
The process of identifying the most valuable sample that needs to be marked next is called "sampling strategy" or "query strategy". The scoring function in this process is called "Acquisition Function". The meaning of this score is that the higher the score data point, the higher the value of the model training after the model training (no model effect is good). There are many different sampling strategies, such as uncertain sampling, diversity sampling, expected model changes ... In this article, we will only pay attention to the uncertainty of the most commonly used strategy.
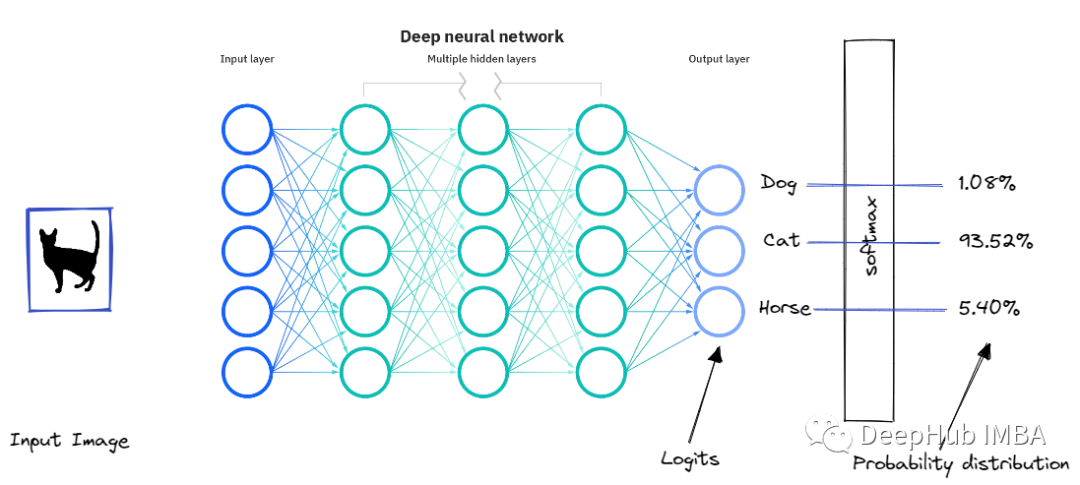
Uncertainty sampling is a set of technologies that can be used to identify unbar samples near the decision -making boundary in the current machine learning model. The richest example here is the most uncertain example of the classifier. The most uncertain sample of the model may be data near the classification boundary. And our model learning algorithm will obtain more information about the boundary boundaries by observing the most difficult samples of these classifications. Let us use a specific example, assuming that we are trying to build a multi -category to distinguish three types of cats, dogs, horses. This model may give us the following predictions:
not : 0.9352784428896497, "Horse": 0.05409964170306921, "Dog": 0.038225741147994995,
This output is likely to come from SoftMax, which uses the index to convert the number of scores to the 0-1 range.
Minimum confidence: (Least Confidence)
The difference between minimal confidence = 1 (100 % confidence) and the most confident label of each project.
Although it can be ranked separately in the order of the reliability, the uncertain score is converted to the 0-1 range, and 1 is the most uncertain score that may be useful. Because in this case, we must standardize the score. We minus this value from 1, multiply the result with n/(1-n) and n as the number of labels. At this time, because the minimum confidence will never be less than the number of labels (when all tags have the same predicting confidence).
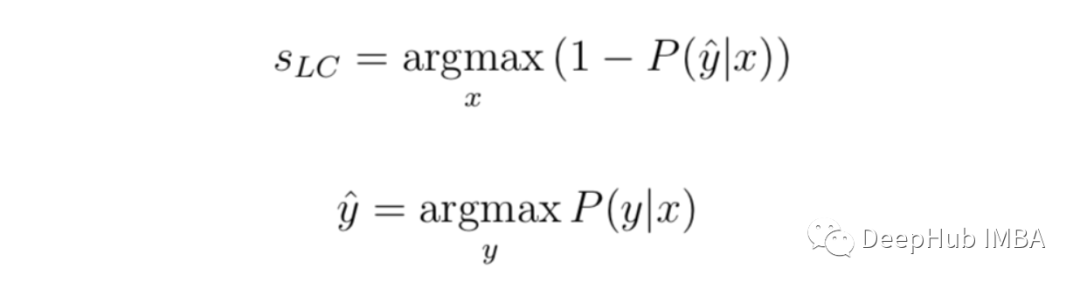
Let's apply it to the example above, and the uncertain score will be: (1-0.9352) *(3/2) = 0.0972.
The minimum confidence is the simplest and most commonly used method. It provides the ranking of the predicted order so that it can sample its prediction tag with the lowest confidence.
Frequent sampling spacing (Margin of Confidence Sampling)
The most intuitive form of uncertain sampling is the difference between the predictions of two confidence. In other words, how much is the difference between the label of the model prediction compared to the second highest label? This is defined as:
Similarly, we can convert it to a range of 0-1, and we must use 1 again to minus this value, but the maximum possibility of score is 1, so there is no need to perform other operations.
Let's apply confident sampling spacing to the example data above. "Cat" and "horse" are the first two. With our example, this uncertain score will be 1.0- (0.9352–0.0540) = 0.1188.
Sample Sampling (Ratio Sampling)
The confidence ratio is the change of the edge of confidence, and the absolute value of the difference between the difference between the two scores rather than the difference between the difference.
Entropy Sampling
Entropy applied to the probability distribution includes the number of probability multiplied by its own pair, and then the negative number is required:
Let's calculate the entropy on the sample data:
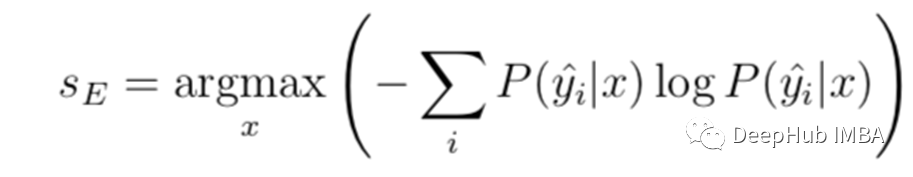
Get 0 -SUM ( - 0.0705, –0.0903, –0.2273) = 0.3881
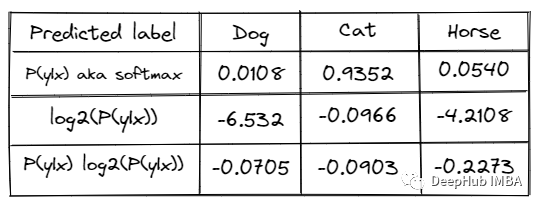
Except for the LOG with the number of labels, 0.3881/ log2 (3) = 0.6151
Summarize
Most of the focus of the machine learning community is to create better algorithms to learn from data. Obtaining useful labeling data is very important during training, but the labeling data may be very laborious and laborious, and if the quality is not good, it will have a great impact on training. Active learning is a direction to solve this problem, and it is a very good direction.
Author: Zakarya Rouzki
Edit: Huang Jiyan
- END -
Focus on psychological services and create a "sunlight" camp

In order to further improve the level of psychological service and promote the con...
This solid shot, super burning!
Video/Snapshot, T_100, F_JPG, M_fast Controls = Controls data-version/ueditor/video/mp4/20220707/16571622831366.mp4 transcoding = 1 style = width: 400px; Recently, at the level of the