WeChat search for smart question and answer technology
Author:Data School Thu Time:2022.07.04

This article is about 7600 words, it is recommended to read for 15 minutes
This article introduces the intelligent Q & A technology in WeChat search.

Follow the following four o'clock:
Background introduction
Questions and Answers based
Q&A based on documentation
Future outlook
01 background introduction
1. From search to Q & A

Search engine is an important way for people to obtain information, which contains many Q & A Query. However, traditional search can only return the Topk webpage. Users need to analyze and identify answers from the webpage to experience poor experience. The reason is that the traditional search engine is only "matching" for Query and DOC, and it is not a real fine -grained understanding Query. Smart Q & A can make up for this limit. Its advantage is that it can better analyze Query and return accurate and reliable answers directly.
2. Common user question and answer needs in search scenarios

A question -and -answer facts Query based on the graph, the answer form is a short answer to the physical phrase. For example, "Andy Lau's Wife", or the entity gathering "four famous works in China", and time/figures.
The second category is view -type Query, and the answer form is "Yes or no", such as "Can high -speed rail escape tickets" and so on.
The third category is the summary Query. Unlike the first two types of short answers, the answer may need to be answered with long -sentence summary, usually "why", "what to do", "how to do" and other questions.
The last category is the list type query, usually the process and step -related questions. The answer needs to be used as a accurate answer with the list.
3. Answer knowledge source

Structural data is from Infobox, which is perpendicular to vertical websites such as encyclopedia, Douban. The advantage is high quality, which is convenient for acquisition and processing; the disadvantage is that it only covers the head knowledge, and the coverage rate is not enough. For example, "who is the height of Yi Jianlian" and "who is the director of Infernal Affairs 1".
Non -structured universal texts are derived from the Internet web page text library of encyclopedia, public accounts and other Internet. The advantage is that the coverage is wide, but the disadvantage is that the quality of the text is uneven, and the coverage and authority of knowledge in professional fields such as medical care and law are not enough.
Non -structured professional vertical websites: Q & A data from vertical sites in professional fields usually exist in the form of question and answer. The advantage is that the knowledge coverage in the professional field is wide and authoritative.
4. Technical route for intelligent Q & A

There are two main technical routes that support intelligent Q & A: KBQA (quiz based on graph -based) and DOCQA (document -based question and answer).
The advantage of KBQA is strong scalability, can query the various attributes of the entity, and support reasoning at the same time, can analyze complex query. For example, an example on the right in the figure, "How high Yao Ming's wife is" can analyze the intermediate semantic expression, thereby converting into a query of the knowledge map and getting the answer to the question. The key technologies involved are graph construction (including SCHEMA construction, entity mining, relationship extraction, open information extraction technology) and problem analysis (including physical links, analysis methods based on Semantic Parsing, and retrieval -based problem analysis methods).
The advantages of DOCQA than KBQA are the problem of wider coverage, covering more medium and long tails, and at the same time, it can solve the problem that it is difficult to analyze by KBQA. For example, the Query, the first unequal treaty in Chinese history, is difficult to analyze into a structured expression. The technologies involved mainly include reading comprehension (MRC) and open domain Q & A (OpenQA).
02 Questions and Answers based on graphics
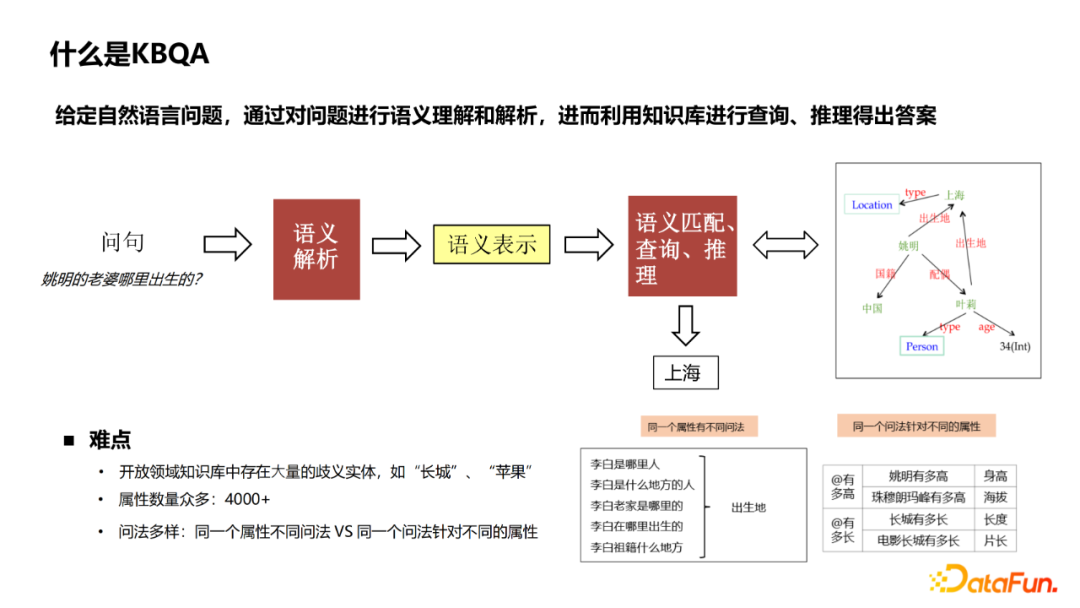
KBQA definition: Given natural language issues, through semantic understanding and analysis of the problem, and then use the knowledge base to inquire and reason to get answers. The main points faced are the following points:
There are a large number of ambiguity entities in the knowledge base in open fields, such as "Great Wall" and "Apple", which may have a variety of types of same names in the knowledge base. The correct entity from Query is a key module in the entire KBQA.
There are many knowledge map attributes in the open domain, and the correct attributes need to be identified from 4000+ attributes.
There are various ways of interrogation in natural language, and the same attributes have different methods. For example, asking Li Bai's birthplace, there can be a variety of different expressions such as "where is Li Bai" and "where is Li Bai's hometown". The same questioning method may also be targeted at different attributes, such as "how high Yao Ming is" and "how high is the Mount Everest", which is also "how high", but the asking attributes are height and altitude.
1. KBQA technical solution

Option 1: retrieval method. Perm the similarity of Query and candidate answers (candidate nodes in the knowledge map) as vector calculation. The advantage is that the end -to -end training can be performed, but the interpretability and scalability are poor, and it is difficult to handle complex types such as limited and aggregate.
Option 2: Analysis method. Patcharge Query into a structured statement that can be queried, and then check in the knowledge map. The advantage of this method is that it is explained, which is in line with the graph that can be understood by people to display the reasoning process, but relies on high -quality analysis algorithms. Considering the advantages and disadvantages, we mainly use this method in actual work.
2. KBQA overall process
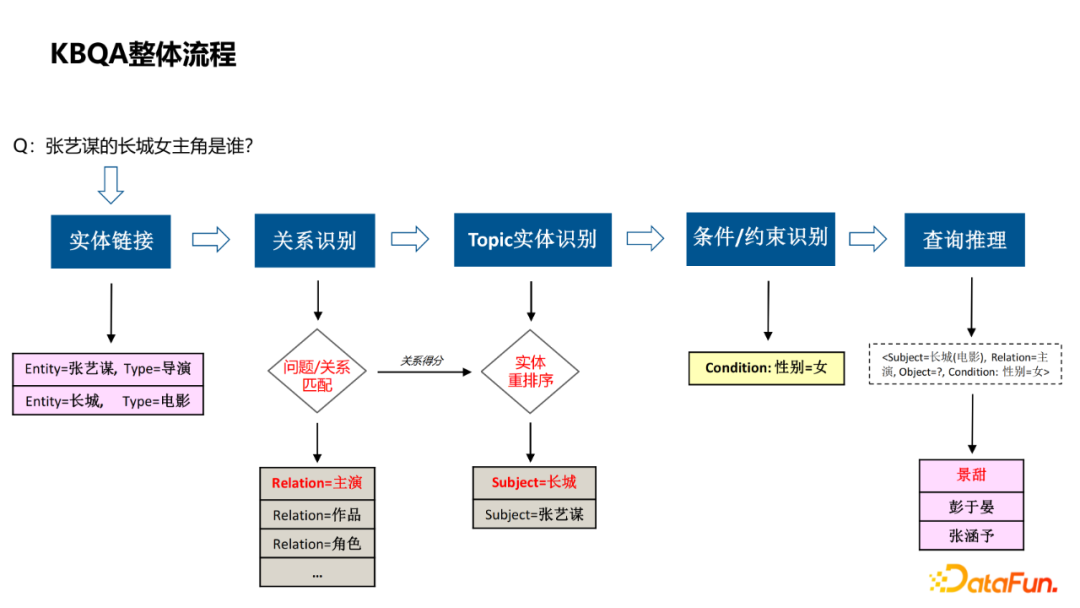
First introduce the overall process of KBQA in one example:
The physical link, identify the entity in Query, and associate it to the nodes in the graph;
Relationship recognition, the specific attributes of Query asked; Topic entity recognition, when Query involves multiple entities, judge which entity is the subject of the problem;
Condition/constraint recognition, analyze some of the constraints involved in Query;
Inquiry reasoning, combine the results of the first few steps into query reasoning sentences, and get answers through the knowledge map.
Throughout the process, the more important thing is the two modules of physical links and relationship recognition. The two modules are introduced below.
3. KBQA-physical link
The entity link recognizes all the entity mesTion from the text, and then links them to the corresponding knowledge map. Here is an example of a physical link.
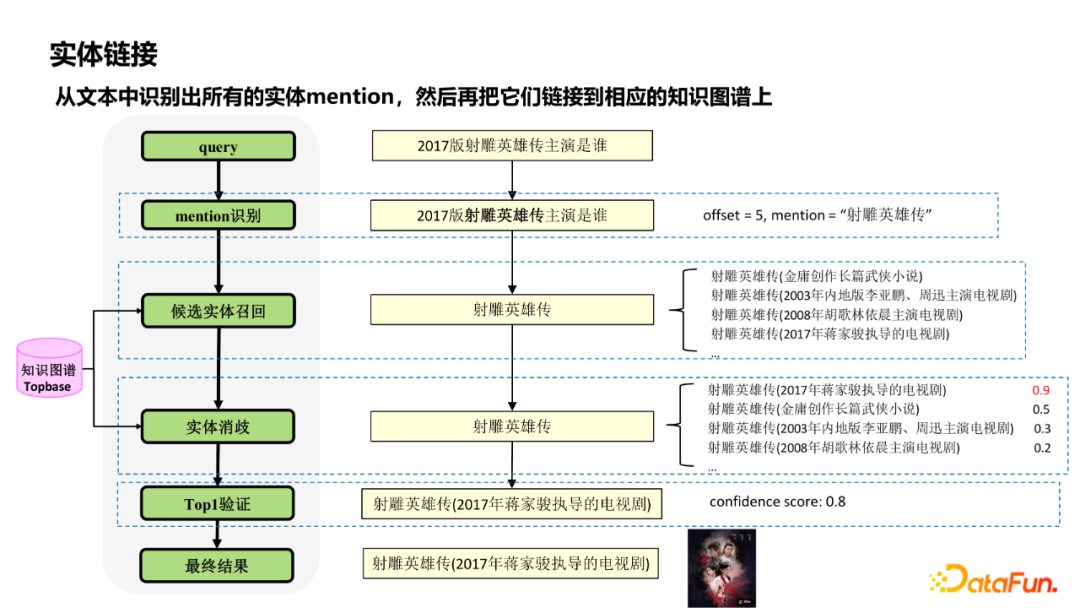
First, through the NER, Spanner and other methods, MENTION identification is performed; according to the identified MENTION, multiple entities are recalled in the knowledge diagram, and physical disaster is performed, which is essentially scoring the recalling entity. Sometimes due to incomplete knowledge map data, there is no corresponding entity in the library. Therefore, there is usually a step "TOP1 verification", that is, the sorted TOP1 result is scored again to determine whether the TOP1 result is the final entity.
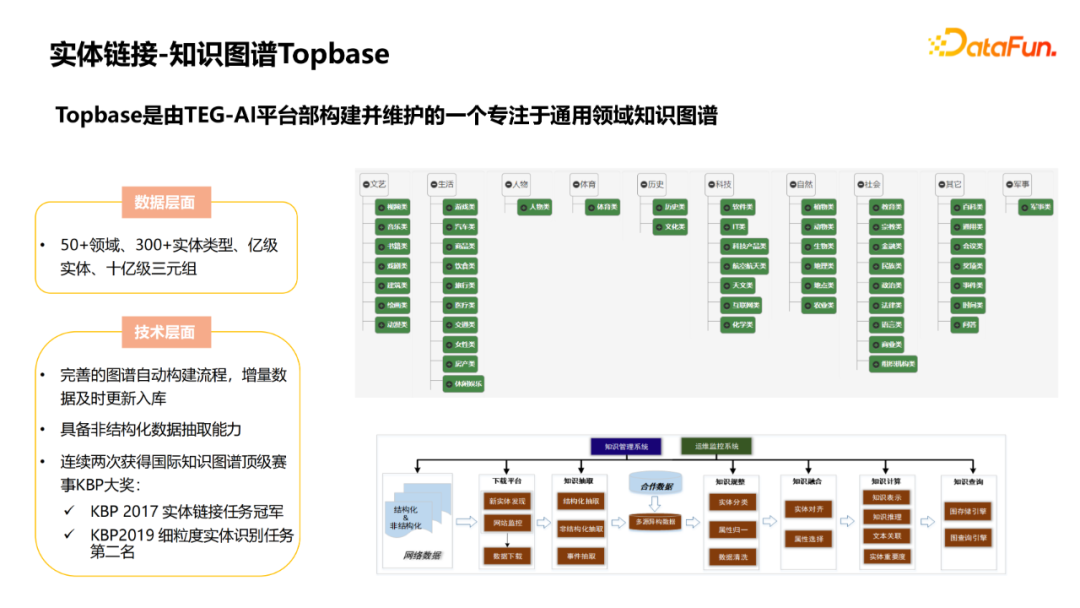
Here we briefly introduce a knowledge map we use at work -Topbase. It is a knowledge map that focuses on the general field constructed and maintained by the Teg-AI platform department. At the data level, there are more than 50 fields, more than 300 entity types, 100 million entities and one billion -level triple groups. We have made a relatively complete automation construction process for this map, including downloading, extraction, noise, fusion, calculation and index steps. Because the structured INFOBOX data may be incomplete, we have also built a non -structured data extraction platform.
Next introduce the candidate entity recall module. The traditional approach is generally using a physical word to make the original name and alias of all entities in the knowledge map into a word table. When recalls, I use Mention as a watch to recall. There are usually two questions:
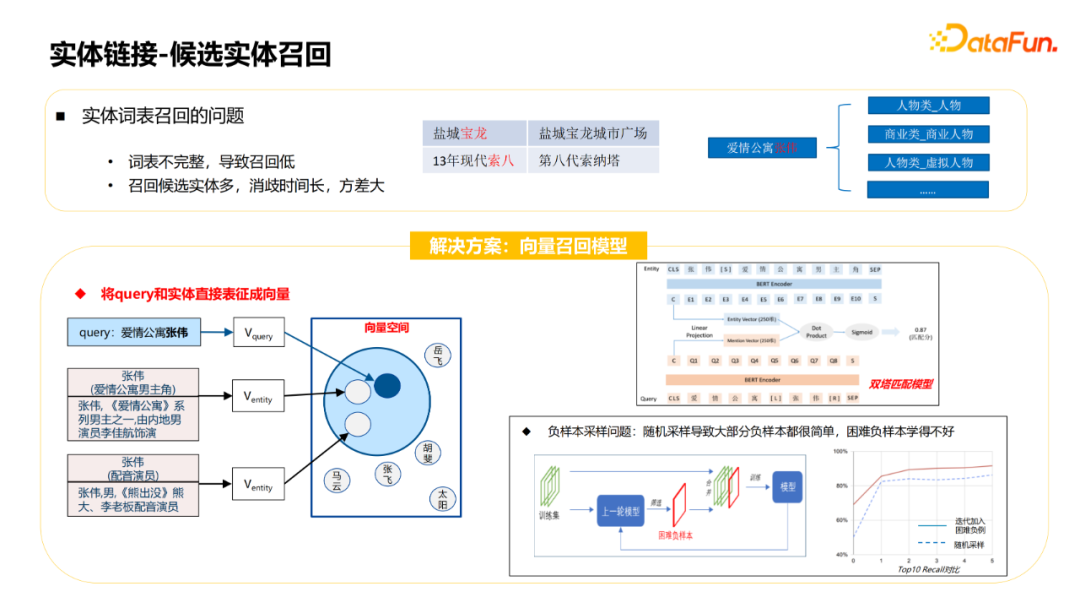
① The incomplete word table leads to a low recall rate. For example, the treasure dragon and Suo Ba in the figure cannot be recalled without excavating aliases.
② There are many entities recalled by some entities, which will cause the later disappearance module to take a long time. For example, Zhang Wei in the figure may have dozens of different types of characters in the knowledge base.
For these two problems, the solutions are mainly based on vector recall: the query and the entity are separated into vectors, and then the similarity is calculated. The matching model is a dual -tower model, and the training data is Query and its corresponding entity message. The candidate entities use names, description information, and profiles as model inputs, and match this model for recall.
There is a problem in the training process. There are many negative cases in this task. If a random sampling method is used directly, most of the negative cases will be relatively simple, making difficulty in difficulty in learning difficulty. The solution adopted is to obtain the candidate entity of Query as a negative example with the previous round of models, and integrate the training model with the current training set to continuously iterate this process. The advantage of this is that in the process of iterative training, each round will add difficulty negative cases, so that the negative cases will be better learned. It can be seen from the table that this training effect is better.
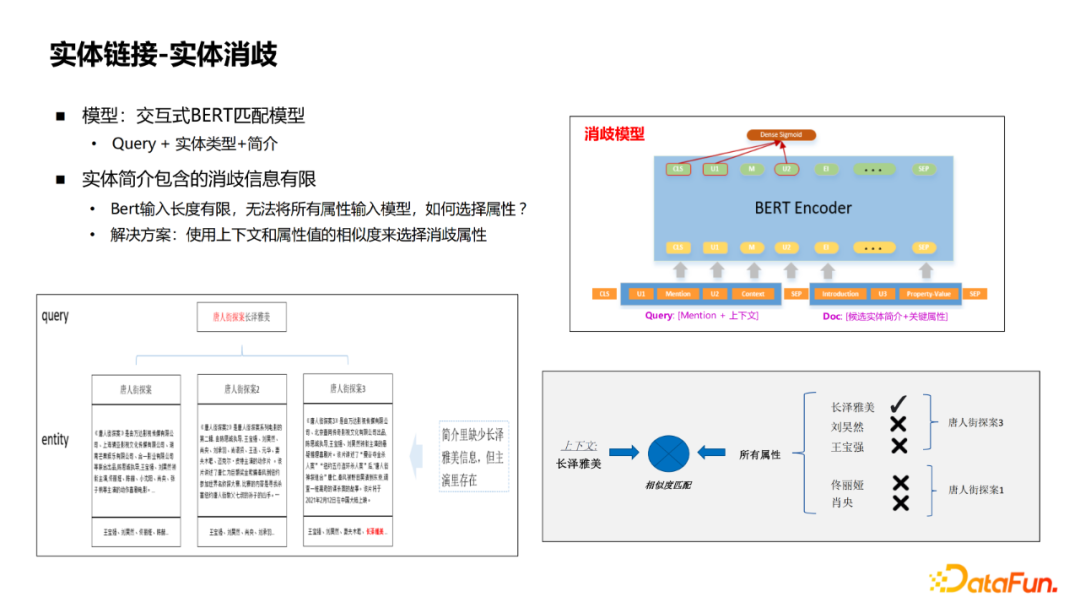
After recalling the entity, the next process is physical disaster. The model adopted is an interactive BERT matching model, which splits the profile and description information of Query and the entity. However, the description of the entity is not enough. For example, in the "Detective of Chinatown", "Nagasawa Masami" did not appear in the profile, only in the actor attribute. Therefore, it is more important to add the attribute values of the entity to the model of elimination. However, the amount of attributes of the entity is very large, and it is impossible to join all. The solution adopted is to recall the attributes. Use the attribute value of Query and the physical attributes to calculate the similarity of lightweight. Wuling up here to do dysfunction.
4. KBQA-Relationship recognition
Relationship identifies which relationship or attributes of the entity. To complete this task, whether it is a method based on a regular strategy or a model -based method, the first thing to do is the template library of digging relationships. The commonly used method is commonly used. The
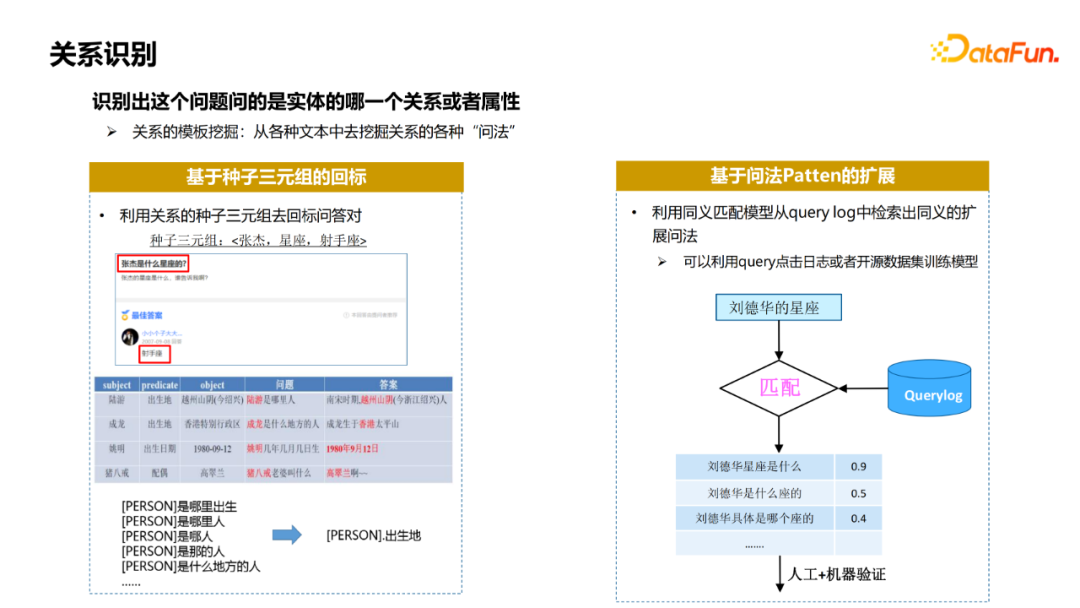
① Based on the bid for the seed three yuan group, this is a more classic method. Find some common three -way groups of attributes and relationships from the knowledge map, and go back to the bid for questions and answers. Like the problem to match the subject, the paragraph answers match the object, there are reason to think that this question is asking this attribute. After matching some data, you can dig out templates for each relationship or attribute through strategy or manual methods.
② For the attributes of the seed asking method, you can use the method of expansion based on the questioning method: use the synonymum matching model to retrieve the extension of synonymous expansion from the Query Log, you can use Query to click log or open source data set training model. After there is a seedlings of a attribute, use this model to match the Query Log to obtain data, combined with artificial or machine verification to obtain the expansion questioning method.
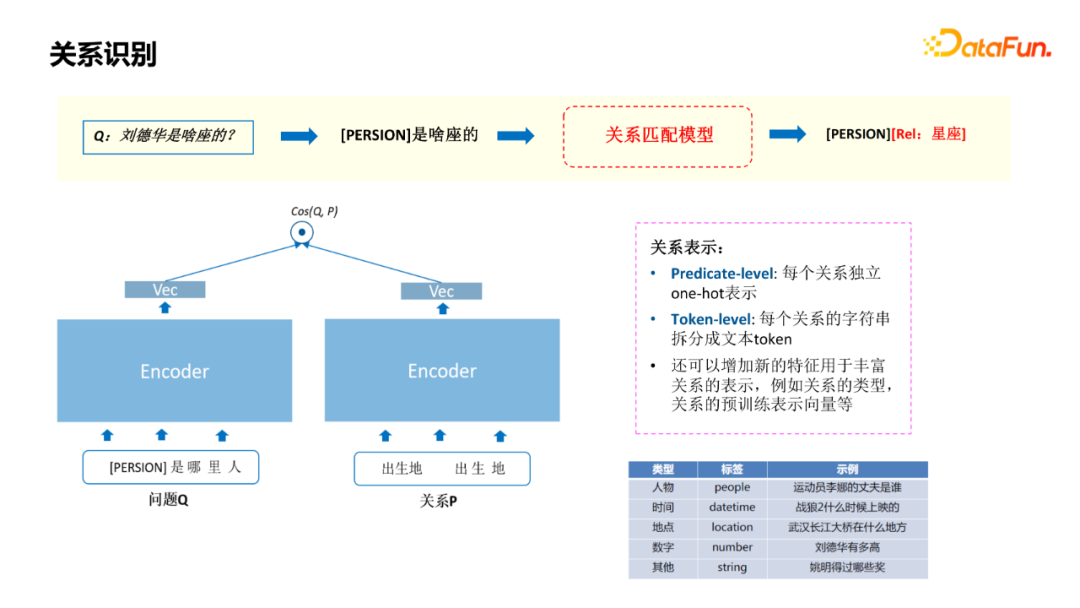
The construction of the template library just introduced, and our model is also based on matching models. As shown on the left, the identified Mention uses its type to replace it, and obtain the vector through Encoder; as shown on the right side, it is the ENCODE of the relationship. There are two parts of the relationship. The first part is the independent One-HOT of each relationship. The second part is to disassemble the string of each relationship into a text token. Another advantage of this model is that some new features can be added, which is used for rich relationships, as shown on the right side of the figure. For example, the object type of relationship, as well as pre -training vector, can further enhance the training effect of the model. In the process of doing the relationship model, there are often problems of poor robustness. The reason is as follows:
① User Query is often short and diverse.
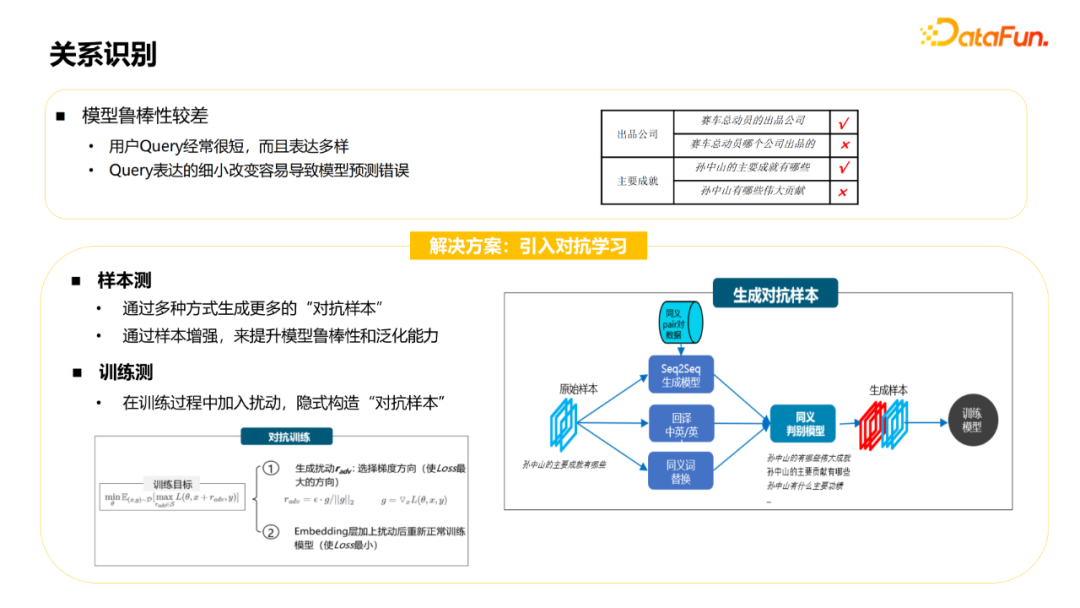
② The small changes expressed in Query can easily cause model prediction errors.
The solution that can be used for this problem is to introduce confrontation learning, mainly used on sample side and training side.
On the sample side, more "confrontation samples" can be generated in multiple ways, and the model robustness and generalization capabilities can be enhanced by sample enhancement. For the original sample, the expansion sample can be generated through the method of SEQ2SEQ, translation or synonym replacement, but there may be some of the samples that are not synonymous, but noise. This can be used in a synonymous model. Or strategy to judge. Finally, the generated samples and original samples are combined together to improve the robustness of the model.
On the training side, you can add disturbance during the training process, and use a confrontation learning method to construct a "confrontation sample". Combat training is generally two steps. The first is to generate disturbances: select the gradient direction (the most direction of LOSS); the second is the Embedding layer and the normal training model after disturbing (the minimum LOSS).
5. KBQA-complex query analysis
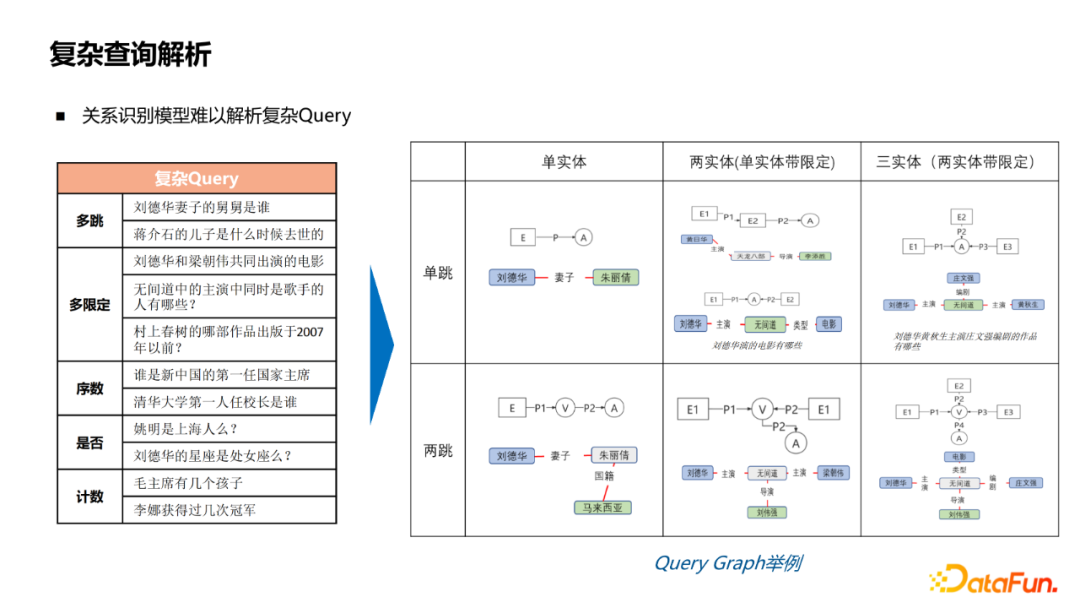
Everyone usually searches for some simple query, but there are also some complex Query. The relationship recognition model just introduced is more difficult to handle complex Query. The figure lists some complicated Query examples, jumping, multi -limited, order numbers, whether and counting the problem is the complex Query type that users often search.
These Query may involve multiple relationships, and there are many entities involved. Therefore, it is difficult to deal with this situation with the relationship identification model just now. Because it is a multi -relationship and multiple entities, it can be expressed as a picture. Here is a few query diagrams. In this way, the simple single entity, single -jump question and answer to Query Graph just now are used. A more complicated graph structure to analyze the more complicated Query.
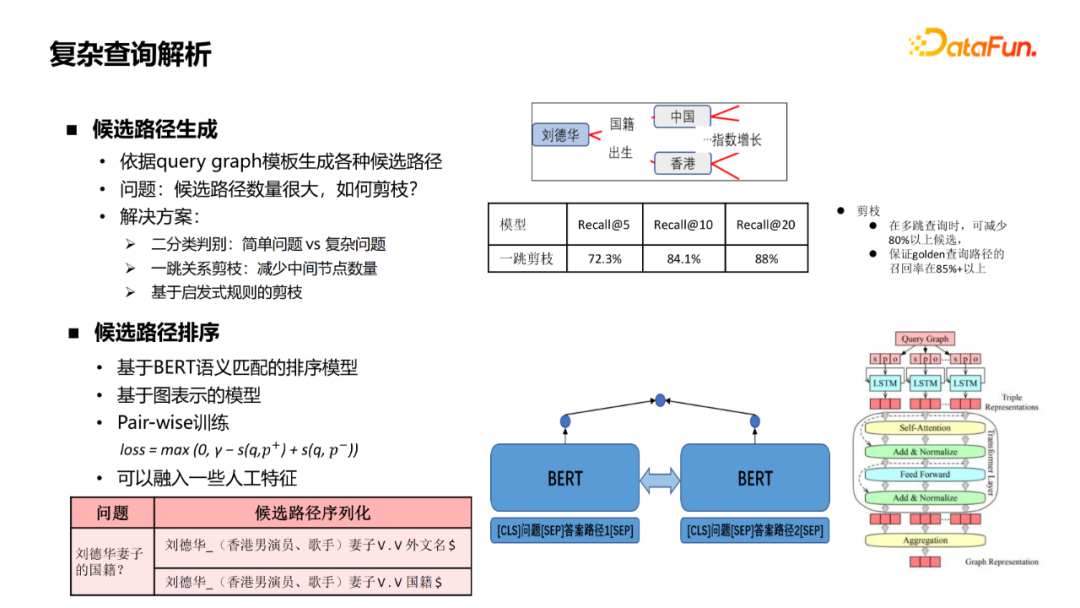
There are two key modules for complex queries, one is the generation of candidate paths, and various candidate paths are generated according to the Query Graph template, but the number of paths generated is very large, several common pruning schemes:
Two classification judgment: simple question or complex problem
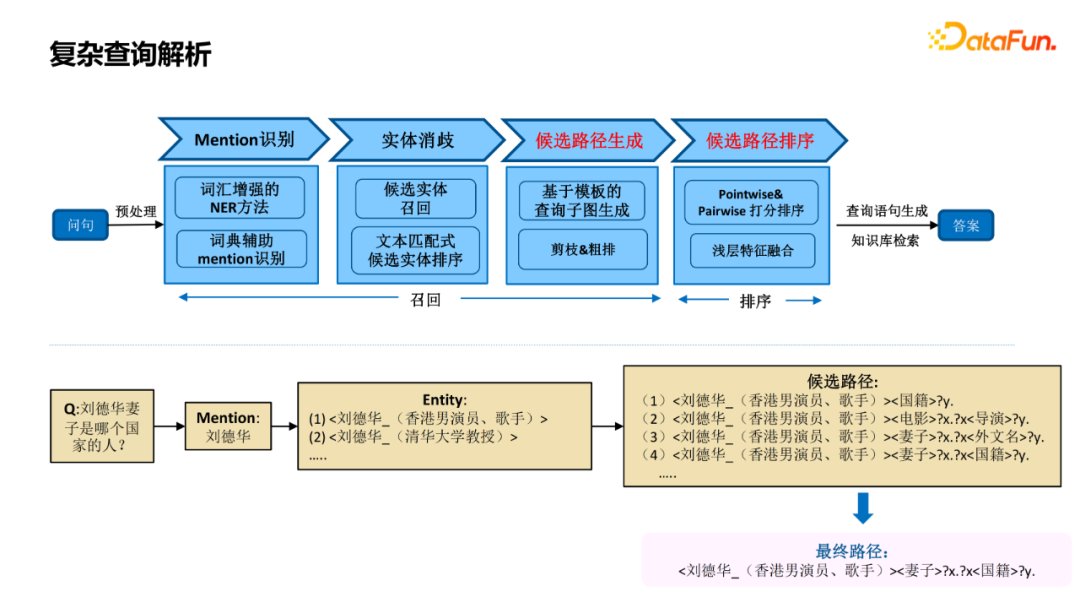
Speed -jump relationship pruning: reduce the number of intermediate nodes
Based on inspiration rules
Through these methods, candidates can reduce 80 % on the basis of ensuring a certain recall rate.
There are generally two schemes for the sorting of the candidate path:
① Sorting model based on Bert semantics. Bert needs to enter a sentence, so the query diagram is serialized into a paragraph of text first, and then searched with the problem stitching to get the matching score, and then training based on the Pair-Wise method. The lack of this method is to serialize the query diagram so that it does not better use the structured information of the graph.
② Model based on graphs. Query Graph is composed of some ternary groups. They go to these three yuan groups to get ENCODE vectors. They use the Transformer layer to do their interaction between them. Finally, they get them up to get the characteristics of the candidate query diagram. This method is better than a serialized method.
In addition to these deep semantics, some related artificial characteristics can be integrated to further improve the effect.
In addition to the method introduced just now, there is also a type of Query parsing method based on grammar -based analysis. Support fast configuration, support complex and new queries.
The grammar indicates the context of no grammar (CFG), and the semantic representation uses abstract semantics (AMR).

As shown in the figure, a simple process is listed. For a Query, you will first do physical and attribute recognition, then label, and then perform syntax analysis based on the grammatical rules configured by labels. For example, classic algorithms such as CYK are formally expressed. Next, the relevant predicate is to be reasonable, that is, some attribute relationships, and finally a actual query is generated.
03 Questions and Answers based on documentation
DOCQA refers to the answer to the use of retrieval+machine reading understanding and other technologies to extract user questions from the open text library. There are a few difficulties:
① The accuracy of the answering fragment is drawn.

② The ability to come to an unknown paragraph. Many times the paragraph does not include answers, so try to avoid extraction answers from paragraphs.
③ The correlation between the recall paragraph and the problem. Only by ensuring correlation can the following model be drawn out of the correct answer.
1. DOCQA overall process ① Filter the Q & A for Query Log.
② Through the retrieval of the module to retrieve some of the corresponding paragraphs in the paragraph library.
③ Make a Reader model (multi-paragraph-MRC) for the retrieved Topk paragraph.
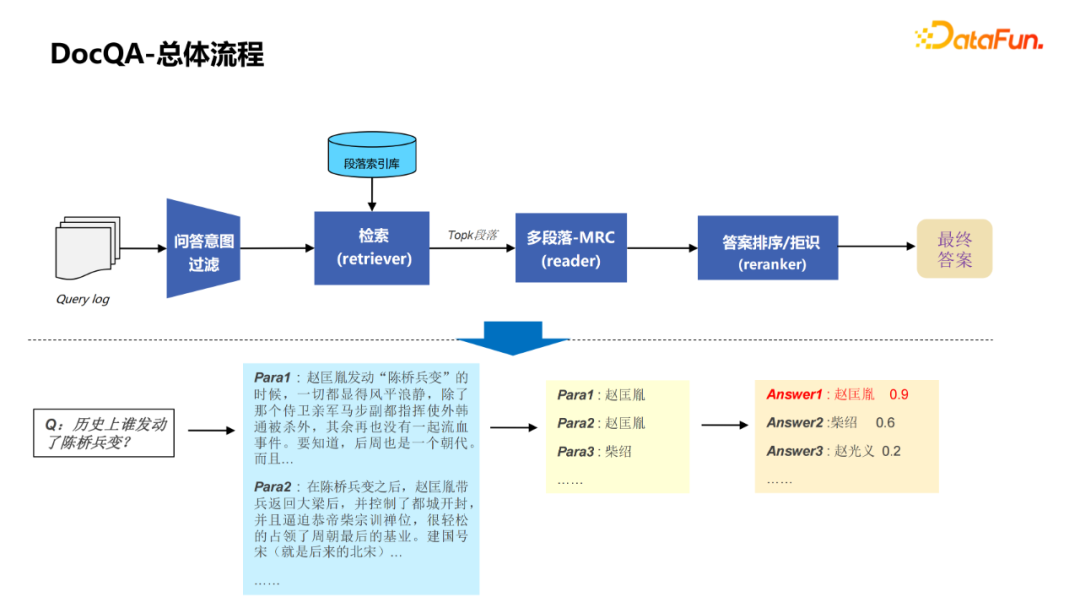
④ Results and rejection of the answer.
⑤ Output the final answer.
It can be seen that the more important thing in the whole process is to retrieve modules and multi -paragraph MRC modules.
2. docqa-semantic search
For retrieval modules, the problems often encountered are as follows:
① Limited samples in specific fields, how to use limited marks to further enhance the generalization of models.
② The inconsistency of training and prediction: During the training process, the matching model is generally used in the Batch Negative method. From the other Query in the Batch It is a full -library retrieval. It may reach millions or tens of millions of scale in the entire library, which will lead to the recall problem during retrieval predictions. Many errors have been recalled. This method will cause inconsistency of training and prediction.
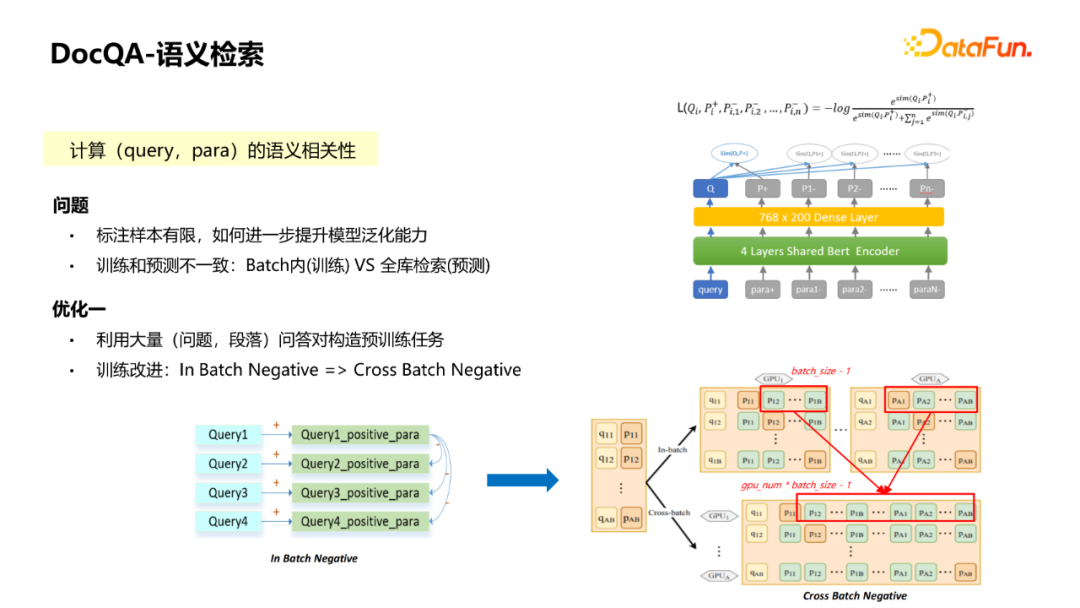

There are several optimization solutions for this problem:
① Using a large (problem, paragraph) Q & A, constructing pre -training tasks through strategies and manual screening some high quality, which is equivalent to improving the effect of the model through secondary training on the basis of the BERT training model. Select Negative from BATCH to select Negative from the outside of BATCH. Generally, when the training matching model is used, if the multi -machine and multi -card method is used, the Query paragraph of other cards can be used as the negative case of the current card. Each one can be. The negative scale of Query will be raised from BATCH_SIZE to GPU_NUM * BATCH_SIZE, so that there will be more negatives seen, and the model will be more fully trained to alleviate the problems of inconsistent training and prediction.
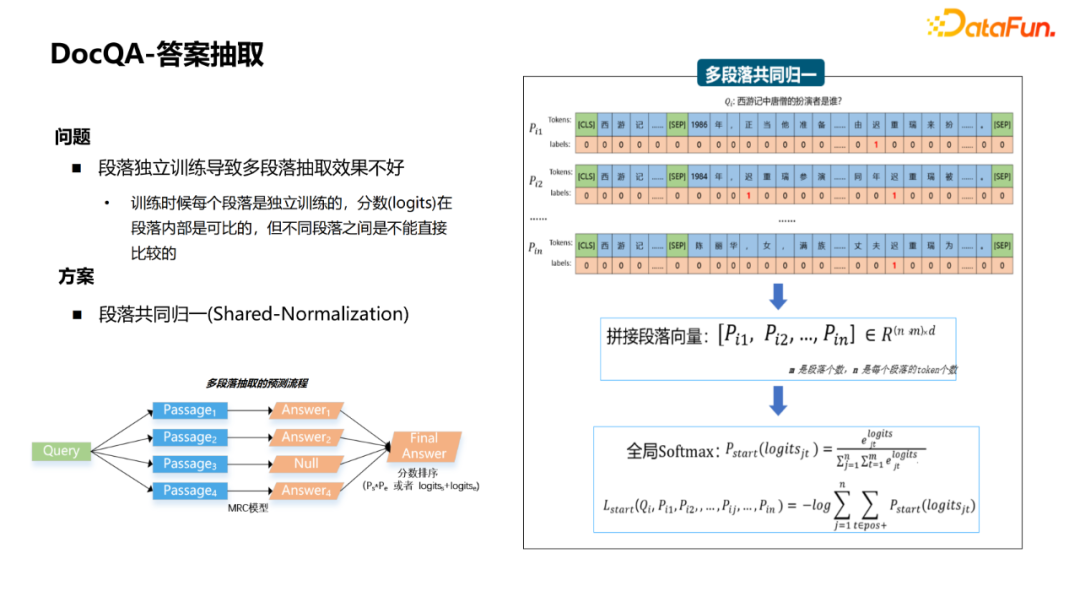
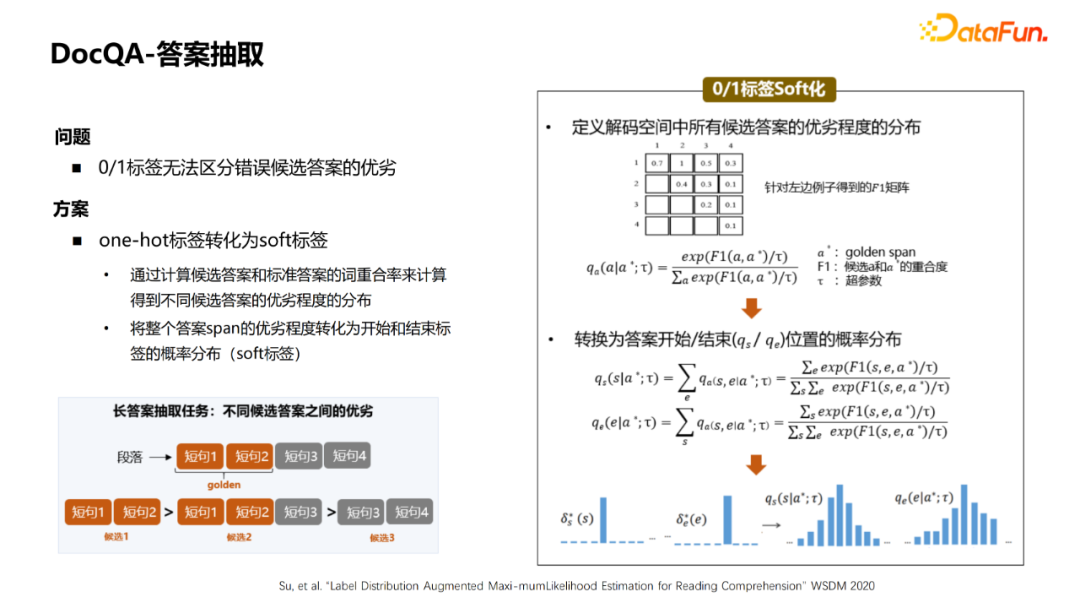
② You can use a large number of The figure is the entire process: First, the QA pair of QA pairs collected by the current model is used to recall the paragraphs of TopK. If it is the first time, you can use the unsupervised method of BM25 to recall the paragraph. After recalling paragraphs, you can use the QA pair A to return to the bid. The bid will be used as a positive example, and those who are not marked as negative. In this way, the generated distant supervision samples and label samples are combined to train the matching model, and then iterates. This iterative method can introduce more difficult negative cases to make the model learn better. 3. DOCQA-Answers extraction Next introduce the answer to extract (MRC). Generally, the physical phrase class (short answer) is extracted, and the problem and paragraph will be pushed together to use a bert to predict the beginning and end of the fragment. However, this method cannot be well applied to the extraction of long answers and whether it is category. At this time, some transformations need to be made. For example, adding a classification diagram to determine whether it is "yes" or "no" for whether the category answers; to the long answer class, to aggregate the sentence, and to aggregate from the token level into a sentence representation. Start and end of the level. For the answer to extract this module, the first question is that the MRC sample labeling cost is high, and it is difficult to obtain samples in large -scale fields. Generally, the pre -training language model (Bert)+FineTune method is used to learn from some knowledge that the pre -training model has learned well, which can greatly improve the model effect. However, MLM and MRC tasks are very different. MLM tasks are mainly Mask some tokens. Use sentences to predict these tokens. Mainly language models such as phrases, grammar and other language models. The MRC is a matter of the answer to the related paragraphs to find the answer to the paragraph, which mainly learns the understanding of the problem and paragraph. Therefore, a better solution for this problem is whether it can build a pre -training task close to the MRC task. One way in the papers last year was to use clips to select Mask+ retrieval to construct pre -training samples similar to MRC. The specific process is as shown in the figure: First of all, you need to have a text library, select some sentences to do physical identification, and then randomly Mask drops the entity and replace it with a pass. At this time, this sentence can be used as a query, and the paragraphs of topk are retrieved in the paragraph library. After the strategy screening, these paragraphs can be used as a sample of SSPT. The form of this sample is relatively close to the form of the MRC sample. The second question is: How to deal with the noise containing the sSPT structure? One of the solutions adopted is to add a new quiz prediction task. Determine whether the noise sample is determined by the semantic correlation between the words and questions around the modeling answer. For a noise sample, the words and questions around the answer items have nothing to do. We hope that the losses of the prediction tasks above and below are large, and the words and questions around the normal sample, the words and questions around the answer items are related, and the loss of the prediction of the task above and below the question and answer is small. There are three steps for specific methods: ① Define the label of each word in the context, and use some of the words in the paragraphs as its related words. We assume that the closer the answer is, the more likely it is to become related words. Therefore, inspiration defines the probability of each word in the paragraph, the probability of the context, which is equivalent to the closer the answer, the higher the probability, the lower the probability, the lower the index level attenuation. ② It is estimated that each word is the probability of context. With BERT's vector and an additional matrix to start and end, it will accumulate the interval of each word to calculate the probability of this word belongs to the context. ③ Label and probability of each word can be obtained at the end, and you can calculate the loss of prediction tasks through the algorithm of cross -entropy. Finally, our loss function is the loss of Answer and the loss of this task. It is hoped that the loss of this noise sample is too large, and the loss of normal samples is smaller. Finally, after the overall loss is defined, the co-teaching de-no-noise algorithm can be used to train the model. The larger the sample loss, the lower the weight to achieve the purpose of the sample to remove the noise. The third problem is that the independent training of paragraphs causes the effect of multiple paragraphs. The picture shows the multi -paragraph extraction process. Each paragraph will be extracted from each paragraph, which will select the final answer based on the score. However, because each paragraph during training is independent training, the score is incompetent between different paragraphs. The scheme that can be used for this problem is that the paragraph is returned together, that is, for each paragraph, after obtaining the vector through the ENCODER, the vector is spliced to make a global SoftMax for global losses. The advantage of this is that the final score is comparable even cross section. There is also a common problem: the predictions start and end the 0/1 label, which cannot distinguish the advantages and disadvantages of the wrong candidate answer. The corresponding solution is to soft the label, and the degree of advantages and disadvantages of different candidate answers can be calculated by calculating the word weight syllabus of candidate answers and standard answers. Convert the advantages and disadvantages of the entire answer SPAN to the probability distribution of the start and end label. First, calculate the advantages and disadvantages of all candidate answers, turn it into a probability distribution, and then get the probability distribution of each answer start/end position. The original 0/1 HARD was transformed into a SOFT representation. 04 Future Outlook ① Analysis of complex issues. In addition to the some just listed, there are actually many complex issues that many users often ask, such as multi -purpose and multi -condition issues. It is difficult to analyze and answer these Query well, and requires more powerful Query Graph representatives and analysis algorithms of more universities. ② Improve the stability of the MRC model. When the question is changed to a question, or the existence in the paragraph is similar to the same type of answer type, and the context is similar to the problem, it is easy to cause model extraction errors. This is also a hot spot in academic research, and there are many achievements, such as adding some confrontation samples or against sentences. This is also a more important job in the future. ③ The physical short answers with conditions and cross -fragmentation are extracted. Many times, although a question is a short answer to the physical phrase class, it may have conditions in the paragraph. Under different conditions, the answer to the short entity may be different. Therefore, not only to draw long sentences, but also more accurate to extract these conditions and conditions corresponding to the conditions. 05QA Q1: Do the seed -based three -yuan group in KBQA need to maintain a standard question and similar question? A1: No need, we will choose some three yuan groups to the attributes, and go back to the marker for some questions and answers. For those questions on the bid, they are suspected of asking this attribute. Do some noise on these issues, coupled with artificial strategy or manual review, finally get the training data with clean each attribute, without involving a table that maintains similar questions. I just introduced a method. After getting some Pattern, I went to the Query Log to match some extended interrogation methods through the synonym. These questions are processed by strategic processing, and finally the relationship between this relationship is obtained. Q2: How can I distinguish between the subject or object in the KBQA relationship recognition? A2: Generally, it will be judged by a model alone during the identification process. Ask whether it is known for SP or based on PO. Q3: How to choose the negative sample in the relationship recognition? How to deal with attributes that are similar but different? A3: If you randomly extract the negative cases, it will be relatively simple. Generally, the method is to introduce artificial methods. For example, expansion questions, synonymous matching this method to obtain samples.When marking, you will naturally look similar to those, but in fact, the wrong questioning method will be marked. Through similar active learning methods, some difficult negative samples are continuously added to improve the accuracy of difficulty in the identification of difficulty samples.That's it for today's sharing, thank you. Edit: Wang Jing - END -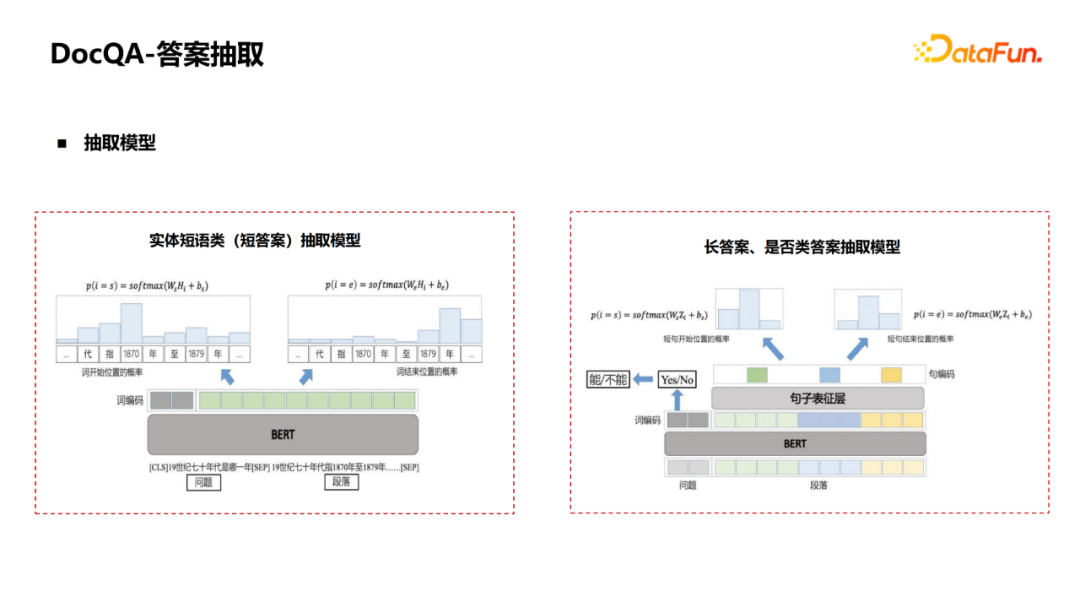


Maternal and baby e -commerce platform honey bud app will stop service

The 8 -year -old maternal and infant e -commerce platform honey bud APP is about t...
"Node+New Products" dual tensile, merchants aim at Douyin Life Service to build a new growth curve

Produced | The front line of entrepreneurshipAuthor | XiaoxinIn this special node ...