MULTIMIX: A small number of supervisors performed from medical images, multi -tasking learning that can be explained
Author:Data School Thu Time:2022.06.30

Source: Deephub IMBA
This article is about 4,000 words. It is recommended to read 10+ minutes
This article discusses you a new semi -supervision and multi -tasking medical imaging method.
In this article, I will discuss a new semi-supervision, multi-tasking medical imaging method called Multimix, Ayana Haque (ME), Abdullah-Al-Zubaer Imran, Adam Wang, DeMetri Terzopoulos. The paper was included by ISBI 2021 and published at the April meeting.
Multimix executes joint semi -supervision classification and division by using confidential enhancement strategies and new bridge modules, and this module also provides interpretability for multiple tasks. Under the circumstances of complete supervision, deep learning models can effectively perform complex image analysis tasks, but its performance is seriously dependent on the availability of large markup data sets. Especially in the field of medical imaging, manual labeling not only costs money, but also takes time. Therefore, the semi -supervision learning from the limited number of label data is considered a solution to the solution to the marking task.
Learning multiple tasks in the same model can further improve the generality of the model. Multi -tasks allow the learning to be shared between tasks. At the same time, fewer parameters and fewer calculations are required to make the model more effective and not easy to overfit.
Different numbers of labeling data and poly source data have been widely experimented, and the paper proves the effectiveness of its methods. It also provides cross -tasks and cross -domain evaluations to show the model to adapt to the potential of challenging generalization scenes, which is a challenging but important task for medical imaging methods.
background knowledge
In recent years, due to the development of deep learning, medical imaging technology based on deep learning has been developed. However, the fundamental problem of deep learning has always existed, that is, they need a lot of markup data to be effective. However, this is a bigger problem in the field of medical imaging, because it is very difficult to collect large data sets and labels, because they need professional knowledge, expensive, time -consuming, and difficult to organize in centralized data concentrations. In addition, in the field of medical imaging, generalization is also a key issue, because the images from different sources are very different in qualitative and quantitative, so it is difficult to use a model in multiple fields to obtain strong performance. These are these. These are these. These are strong. The problem promoted the study of the paper: I hope to solve these basic problems through some key methods centered on semi -supervision and multi -tasking learning.
What is semi -supervised learning?
In order to solve the limited label data problem, the semi -supervision (SSL) as a promising alternative method has received widespread attention. In the semi -supervision learning, the useless examples are used in conjunction with labeling examples to maximize information benefits. There are a lot of research on the study of semi -supervision, including the general and medical field. I will not discuss these methods in detail, but if you are interested, there is a list of prominent methods for your reference [1,2,3,4].
Another solution to solve limited sample learning is to use data from multiple sources, because this increases the number of samples in the data and the diversity of data. But this is challenging, because a specific training method is required, but if it is done correctly, it can be very effective.
What is multi -task learning?
Multitastask Learning (MTL) has proven to improve the generalization capabilities of many models. Multi -task learning is defined as an optimization of multiple losses in a single model, and multiple related tasks are completed by sharing representation. Jointly training multiple tasks in a model can improve the generalization of the model because each task affects each other (selecting related tasks). Assuming the training data comes from different distributions, so that it can be used for limited different tasks. Multi -tasks are useful in such scenarios for rarely supervising ways. Combining multi -task with semi -supervisors can improve performance and succeed in these two tasks. At the same time, it is very beneficial to complete these two tasks, because a separate deep learning model can complete these two tasks very accurately.
Regarding the related work in the medical field, the specific methods are as follows: [1,2,3,4,5,6,7,8,9,10]. However, the main limitations of these discoveries are that they do not use data from multiple sources, limiting their generalization, and most of the methods are single task methods.
Therefore, the paper proposes a new, more common multi -tasking model Multimix, which combines confident bridge blocks to divide the diagnostic classification and anatomical structure from the Chinese Communist Party. The obvious diagram can analyze the model prediction through visual and meaningful visual features. There are several ways to generate significant mapping. The most significant method is to enter the gradient of the score of the class score from the input image. Although any deep learning model can study better interpretation through significant diagrams, as far as we know, the significant bridges between the two shared tasks in a single model have not been explored.
algorithm
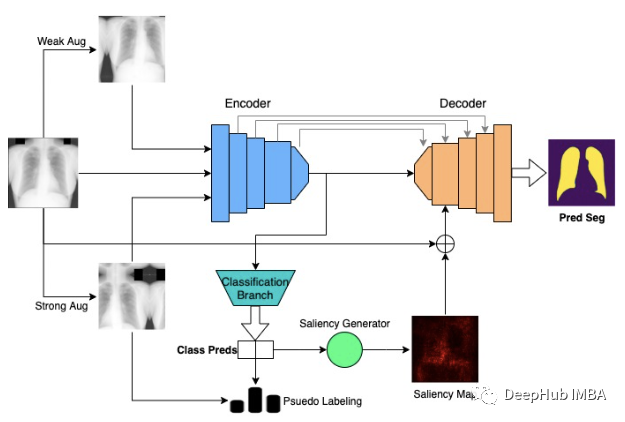
Let us first define our problems. Two datasets for training, one for division and one for classification. For segmentation data, we can use symbol XS and Y, which are images and segmentation masks. For classification data, we can use symbol XC and C, that is, image and class tags. The model architecture uses the baseline U-Net architecture, which is a commonly used segmentation model. The function of the encoder is similar to the standard CNN. To use U-Net to perform multi-tasking processing, we will branch from the encoder and use pooling and full-connected layer branches to obtain the final classification output.
Classification
For classification methods, use data enhancement and pseudo bids. Inspired by [1], an unsigned image was used and two separate enhancements were performed.
First of all, unsigned images are weakly enhanced, and from the weak enhancement version of the image, the prediction of the current state of the model is determined as a pseudo -label. This is why the method is semi -supervised, but we will discuss the label of the pseudo -mark later.
Secondly, strengthen the same unsigned image, and use weak enhancement images and strong enhanced images to calculate the loss of losses.
The basics of such operational theory is to hope that the model will mappore the weak enhancement image to the strong enhanced image, which can force the model to learn the basic basic characteristics required for diagnosis and classification. Enhance the image twice can also maximize the potential knowledge income of the unique image. This also helps improve the general ability of the model, just like the most important part of the model is forced to learn the image, it will be able to overcome the differences in images that appear due to different domains.
The thesis uses conventional enhancement methods to perform weak enhanced images, such as horizontal flipping and slight rotation. The strong enhancement strategy is much more interesting: creating an unconventional, powerful enhanced pool, and applying the random number to any given image. These enhancements are very "perverted", such as cutting, self -contrast, brightness, contrast, balance, consistency, rotation, sharpness, shear, and so on. By applying any number of these elements, we can create very wide images, which is especially important when processing low sample data sets. We finally discovered that this enhancement strategy is very important for strong performance.
Now let's go back to discuss the process of pseudo labels. If the confidence of the model generated pseudo -labels exceeds the threshold of a tone, the image label can prevent the model from learning from error and bad labels. Because when the prediction is not confirmed at the beginning, the model is mainly learned from the marked data. Slowly, the model becomes more confident about the labeling of the unsigned image, so the model becomes more efficient. In terms of improvement, this is also a very important feature.
Now let's take a look at the loss function. Classification loss can be modeling with the following formulas:
Among them, L-SUB-L is a supervision loss, C-HAT-L is a classification prediction, C-L is label, Lambda is unsupervised classification weight, L-SUB-U is an unsupervised loss, C-HAT-S is a strong enhanced image that enhances images It is predicted that ARGMAX (C-HAT-W) is the fake label of the weak enhancement image, and T is the pseudo-label threshold.
This basically summarizes the classification method, and now we continue to talk about the division method.
segmentation
For segmentation, predictions are predicted by the encoder-decoder architecture with a jump connection, which is very simple. The main contribution of the paper to the segmentation is to merge a bridge connection module to connect two tasks, as shown in the figure above. According to the classification of the model prediction, the gradient from the encoder to the classification branch is expanded from the encoder. The entire process is shown above, but it essentially emphasizes the models of the model to classify the image of pneumonia images.
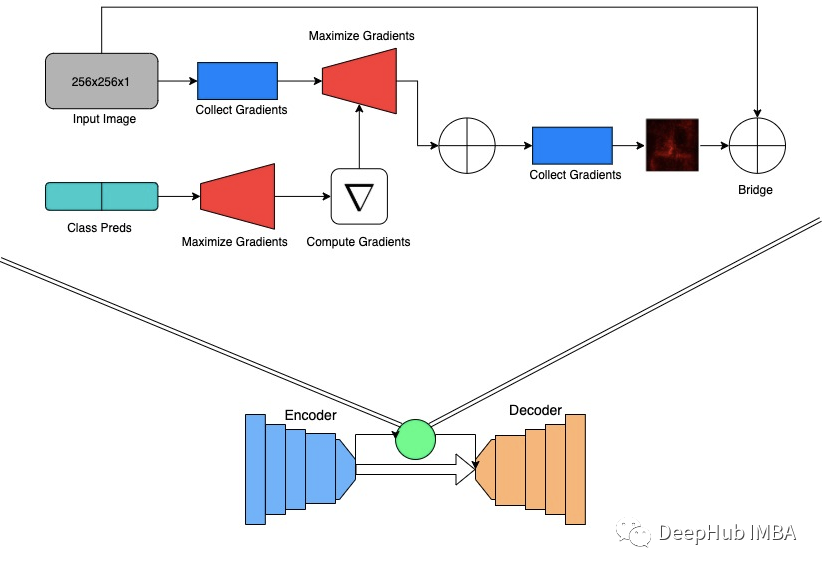
Although we do not know whether the segmentation image represents pneumonia, the generated map highlights the lungs. Therefore, when the classes that use significant graphs and visual images are used to some extent, it is similar to the pulmonary mask to some extent. Therefore, we assume that these diagrams can be used to guide the division of the decoder phase, and can improve the segmentation effect, and at the same time learn from limited tag data.
In Multimix, the generated significant mapping is connected to the input image, performs sampling, and adds to the feature mapping that is entered to the first decoder stage. The connection with the input image can enhance the connection between the two tasks and improve the effectiveness of the bridge module (provided the context). At the same time, adding input images and significant mapping provides more contexts and information for the decoder, which is very important to process low sample data.
Let's discuss training and losses now. For label samples, we usually use DICE losses between reference lung mask and predictive segmentation to calculate the segmentation loss.
Since we do not have the segmentation mask of an unbarly divided sample, we cannot directly calculate their segmentation losses. Therefore, the KL scattering between the division prediction of the calculation marker and the unsigned example. This makes the model make the predictions that are increasingly different from the marked data, which can make the model more appropriately suitable for unbar data. Although this is a method of indirect calculation loss, it still allows a lot of things to be allowed to have a different segmentation data that has never been marked.
Regarding losses, the loss of losses can be written:
Compared with classification, Alpha is the weight reduction, Y-HAT-L is a marked segmentation prediction, Y-L is the corresponding mask, Beta is an unsupervised division weight, and Y-HAT-U is an unsigned segmentation prediction Essence
The model uses a combination of classification and segmentation loss for training. data set
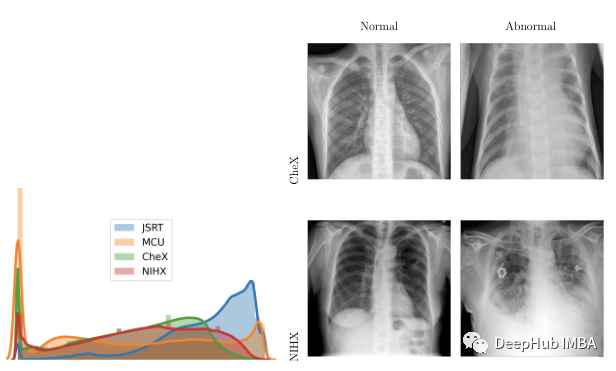
Training and testing the models of classification and segmentation tasks. The data of each task comes from two different sources: pneumonia test data set. We call it Chex [11] and Japan Radiology Technology Society or JSRT [12] [12], used for classification and division, respectively.
In order to verify the model, two external data sets of Mongolian Marie County's chest X -ray or MCU [13], and the sub -sets of NIH breast X -ray data set, we call it NIHX [14]. The diversity of the source constitutes a major challenge to the model, because the difference between the quality, size, size, normal images and abnormal images, and the strength distribution of the strength of the four data sets are very different. The figure below shows the difference in the strength distribution and the image example of each data set. All 4 datasets use CC by 4.0 licenses.
result
There are many experiments on the paper, and different numbers of marking data are used in multiple data concentrations and cross -domain.
Multiple baselines are used in the test, starting from Arale-Net and Standard Classifier (ENC). This classifier is a dense layer encoder extractor. Then, we combine the two into the baseline multi -task model (UMTL). It also uses multi-tasking models of semi-supervision methods (ENCSL), (UMTLS) and multi-tasking models and semi-supervision methods (UMTLS-SSL).
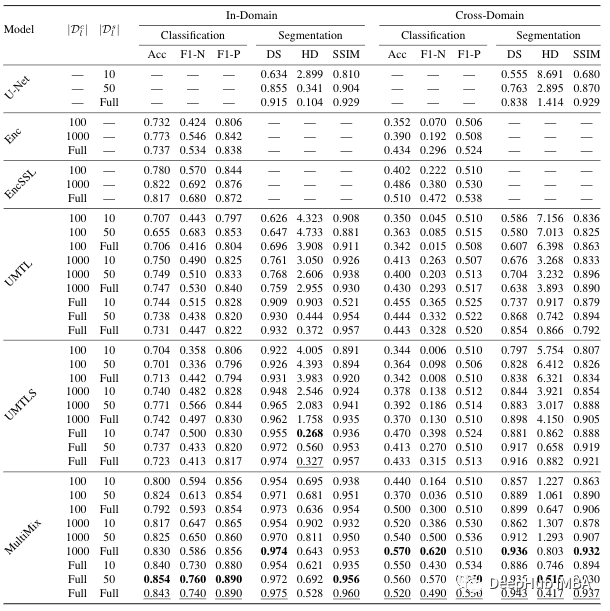
In terms of training, training is conducted on multiple labeled datasets. In order to classify, we used 100, 1000 and all tags. For division, we used 10, 50 and all tags. For the result, the symbol: model -label (such as Multimix -10–100) is marked. In order to evaluate, use accuracy (ACC) and F1 scores (F1-N and F1-P) for classification, and divide ), The average HAUSDORFF distance (HD), accuracy (p) and recall (R).
The table shows how the model performance of each new component is added. For classified tasks, compared with the baseline model, confident -based enhancement methods can significantly improve performance. Multimix-10–100 is also better than the basis of complete supervision in accurate ways. In order to divide, the bridge module has greatly improved the baseline U-Net and UMTL models. Even with the minimum segment label, we can see its performance increase by 30 %, which proves the effectiveness of the Multimix model proposed in the paper.
As shown in the table, the performance in multi -mode is as hopeful as the internal domain. In all baseline models, Multimix scores better in classified tasks. Because there are significant differences in Nihx and CHEX data sets, as mentioned earlier, the score is not as good as the internal domain model. But it is indeed better than other models.
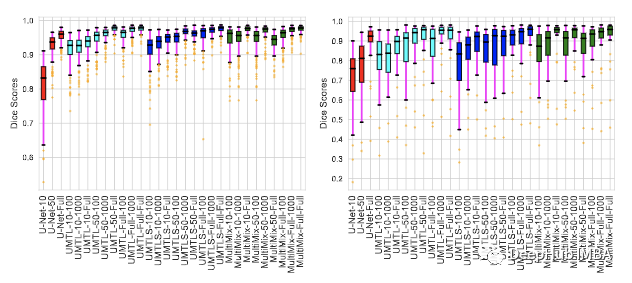
The above figure shows the consistency of the segmentation results for internal domain and cross -domain assessment. Each image of my data set shows the DICE score of the model. From the figure, we can see that Multimix is the strongest model compared to the baseline.
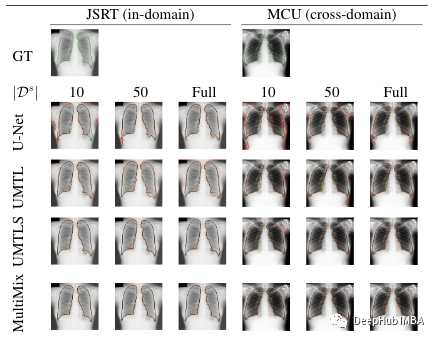
The last picture is the visualization of the division prediction of the model. The borders of the prediction of prediction are compared to the true values of different tag data for each segmentation task. The figure shows the intense consistency of Multimix's boundary prediction for the real boundary, especially compared with the baseline. For cross -domain Multimix is also the best extent, showing strong generalization capabilities.
Summarize
In this article, we explained a new sparse monitoring multi -tasking learning model Multimix, which can be used for joint learning and dividing tasks. This paper uses four different chest X -ray data sets to perform extensive experiments, which proves the effectiveness of Multimix in the domain and cross -domain assessment.
The author of the thesis also provides the source code. Those who are interested can take a look:
https://arxiv.org/abs/2010.14731
https://github.com/ayaanzhaque/multimix
Author: ayaan haque
Edit: Huang Jiyan
- END -
Gesture interactive "fluttering"?3D TOF is not worth the value

The popularity is high to the official website melting, and the ideal L9 will be f...
Jingdong 618 opens the first year of the supply chain value with a responsible supply chain

29 days ago, at the launch conference of Jingdong 618, JD.com proposed to use the ...