[New Book of Manning] Getting Started by Natural Language Treatment
Author:Data School Thu Time:2022.09.25

Source: Specialty
This article is introduced by books. It is recommended to read for 5 minutes
This book can be used as a comprehensive guide through a series of practical applications.

The main purpose of writing this book is to help you understand how exciting the NLP field is, how unlimited the possibility of working in this field, and how low the current threshold is. My goal is to help you start in this field easily and show you how wide applications you can achieve in a few days, even if you have never worked in this field before. This book can be used as a comprehensive guide through a series of practical applications. If you are only interested in some actual tasks, you can also be used as a reference book. When you finish reading this book, you have already learned:
https://www.manning.com/Books/getting-started-with-natural-Language- part=about%20the%20book ,User%2C%20ACH20MUCH%20More.
Understand the basic NLP task and can identify any specific tasks encountered in the actual scenario. We will cover popular tasks such as emotional analysis, text classification, and information search.
A whole set of NLP algorithms and technologies, including stem extraction, word -shaped reduction, word marking, etc. You will learn how to apply a series of practical methods to text, such as vectorization, feature extraction, supervision, and unsupervised machine learning.
The ability to organize the NLP project and what steps are needed in actual projects.
Comprehensively understand the key natural language processing, as well as machine learning and terms.
For the comprehensive knowledge of available resources and tools for natural language processing.
The first two chapters of this book introduce you to the field of natural language processing and various available NLP applications. They also show you how to build your own small applications with the least NLP expertise and skills. If you are interested in a rapid start in this field, I recommend reading these two chapters. Each subsequent chapter studies specific NLP applications more deeply, so if you are interested in any such specific application, you can only pay attention to the specific chapter. If you want to fully understand this field, technology and applications, I suggest you read this book from beginning to end:
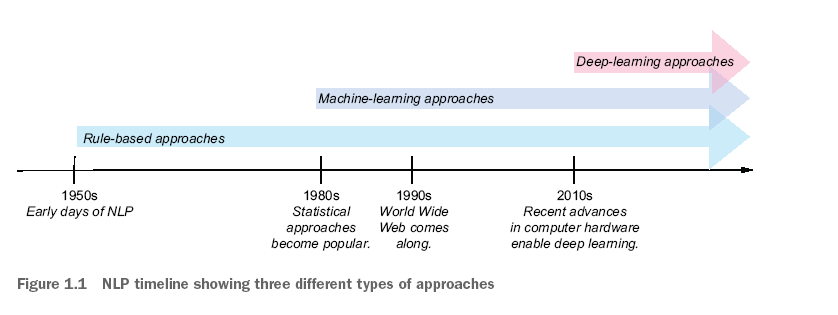
Chapter 1 Introduce the NLP field and its various tasks and applications. It also briefly outlines the history of this field and shows how NLP applications are used in our daily life.
Chapter 2 explains how to build its own actual NLP application (spam filtering) from scratch, and take you to complete all the basic steps in the application pipeline. At the same time, this article introduces some basic NLP technologies, including words and text standardization, and shows how to use them in practice through popular NLTK tool packages.
Chapter 3 mainly discuss information retrieval tasks. It introduces several key NLP technologies, such as sterilization extraction and deletion of deletion, and shows how to achieve its own information retrieval algorithm. It also explains how to evaluate this algorithm.
Chapter 4 discusses information extraction and further introduces some basic technologies, such as polymarks, word elements, and dependence analysis. In addition, how to use another popular NLP tool package Spacacy to build information extraction applications.
Chapter 5 shows how to realize your own authors (or users) analysis algorithms, providing further examples and practice in NLTK and Space. In addition, this article uses the task as a text classification question, and shows how to use the popular machine learning library Scikit-Learn to achieve a machine learning classifier.
Chapter 6 Continue the theme of the author (user) at the beginning of Chapter 5. It studied the task of language characteristics engineering in depth, which is an indispensable step in any natural language processing project. It shows the result of how to use NLTK and Space to perform language feature engineering and how to evaluate text classification algorithms.
Chapter 7 Start the theme of emotional analysis, which is a very popular NLP task. It applies a dictionary method for mission. Emotional analyzers are built using space pipes with space.
Chapter 8 Continue emotional analysis, but unlike Chapter 7, it uses a data -driven method to complete this task. Using SCIKIT-Learn to apply several machine learning technologies, and introduced further language concepts through space and NLTK language resources.
Chapter 9 outlines the task of theme classification. Compared with the previous text classification tasks, it is a multi-class classification problem. Therefore, this chapter discusses the complexity of this task and shows how to use Scikit-Learn to implement a theme classifier. In addition, this article also adopts the perspective of unsupervised machine learning, and shows how to deal with this task as a clustering problem.
Chapter 10 introduces the theme modeling task of the potential Dilikley allocation (LDA). In addition, this article also introduces a popular toolkit called Gensim, which is particularly suitable for using the theme to build an algorithm. This article discusses the motivation, details and results of the LDA method.
Chapter 11 End this book with a key NLP task called the name of the name entity identification (NER).While introducing this task, this chapter also introduces a series of powerful sequence labeling methods widely used for NLP tasks, and shows how NER integrates to further downstream NLP applications.


- END -
Why is "you look far away when you look at me, you look close to the cloud"?Because Yun really looks good!

You look at me in a while, and look at the cloud for a while. I think you look far...
How many Internet accounts do your mobile phone number are associated with?The Ministry of Industry and Information Technology "One Certificate Inspection 2.0" is here!
How many Internet accounts are related to your mobile phone number under your name...