Feature selection in time sequence: speed up the prediction while maintaining performance
Author:Data School Thu Time:2022.09.24

Source: Deephub IMBA
This article is about 1500 words, it is recommended to read for 5 minutes
It shows the effectiveness of feature selection in reducing the time of prediction reasoning.
When we model data, we should first establish a standard baseline scheme, and then modify the scheme by optimization. In the first part of the project, we must invest time to understand business demand and conduct full exploration analysis. Create a original model. It can help understand data, adopt appropriate verification strategies, or provide data support for introducing peculiar ideas.
After this preliminary stage, we can choose different optimization methods according to different situations, such as changing models, processing data, and even introducing more external data.
For each scheme, we need to process, model and verify the data, which requires re -training models from scratch. At this time, we will waste a lot of time. If we can use some simple and effective techniques to improve Forecast speed. For example, we all know that feature selection is a technology that reduces the characteristics of the characteristics of the input of prediction models. Feature selection is an important step in most machine learning pipelines, which are mainly used to improve performance. When reducing features, the complexity of the model is reduced, thereby reducing the training and verification time.
In this article, we show the effectiveness of the feature selection in reducing the time of prediction and reasoning, while avoiding the significant decline in performance. TSPIRAL is a Python package that provides various prediction technologies. And it can be perfectly integrated with Scikit-Learn.
In order to perform experiments, we simulated multiple time sequences, the frequency and double seasonality of each hour (daily and weekly). In addition, we also added a trend from a smooth random walk, so that a random behavior was introduced.
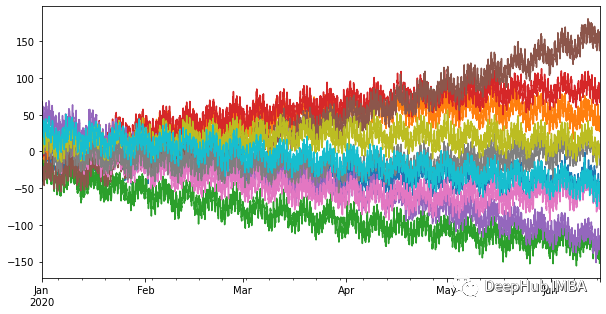
The last part of this sequential data is used for testing. We will record the time to measure the prediction error and make the time required for prediction. This experiment simulated 100 independent time sequences. The reason for "independence" is because although they show very similar behaviors, all the series are not related to each other. In this way, we model them separately.
We use the lagging value of the target as the input to predict the time sequence. In other words, in order to predict the value of the next hour, we use the format format to re -arrange the previously available observation values. In this way, the feature selection of time sequence prediction is the same as the standard table supervision task. The algorithm of this feature selection can simply operate the lagging target features. The following is an example of recursive prediction for feature selection.
from sklearn.linear_model import Ridge from sklearn.pipeline import make_pipeline from sklearn.feature_selection import SelectFromModel from tsprial.forecasting import ForecastingCascade Ridge (), Threshold = 'Median', max_lags = 72 recursive_model = foreastingCascade ( max_features = max_lags, ), ), lags = Range (1,169), use_exog = false ) recursive_model.fit ( None, y) selectd_lags = recursive_model.ESTIMATOR
We use the importance weight of the meta estimator (the coefficient of the linear model) to select important features from the training data. This is a simple and fast method of choosing features, because our processing data can be performed using the same technology that is usually applied to the return task of table regression. In the case of direct prediction, a separate estimator needs to be combined for each prediction step.
You need to choose for each prediction step. Each estimated device chooses different important degree of lagging subsets, and summarizes a set of unique and meaningful lag.
from sklearn.linear_model import Ridge from sklearn.pipeline import make_pipeline from sklearn.feature_selection import SelectFromModel from tsprial.forecasting import ForecastingChain max_lags = 72 Direct_model = ForecastingChain ( Make_pipeline ( ), Ridge () ), n_estimators = 168, lags = Range (1,169), use_exog = false, n_jobs = -1 > Direct_model.fit (None, Y) selectd_lags = np.argsort (np.asarray ([ EST. Est. Estimator _ ['Selectfrommodel']. Get_support () for Est in Direct_model.ESTIMATORS _ ). Sum (0)) [-max_lags:]
As a result, it can be seen that lag choice is closely related to the performance of the model. In the case of pure self -regression, if there is no additional exogenous variables, the lagging target value is the only valuable information that provides good predictions.
Three recursive and direct methods are used here. First, use all the latency (Full) of 168 hours. Then use only dummy. Finally, we only consider the meaningful lag (Filtered) selected on the training data to fit our model.
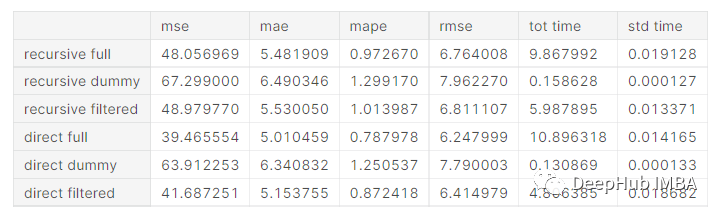
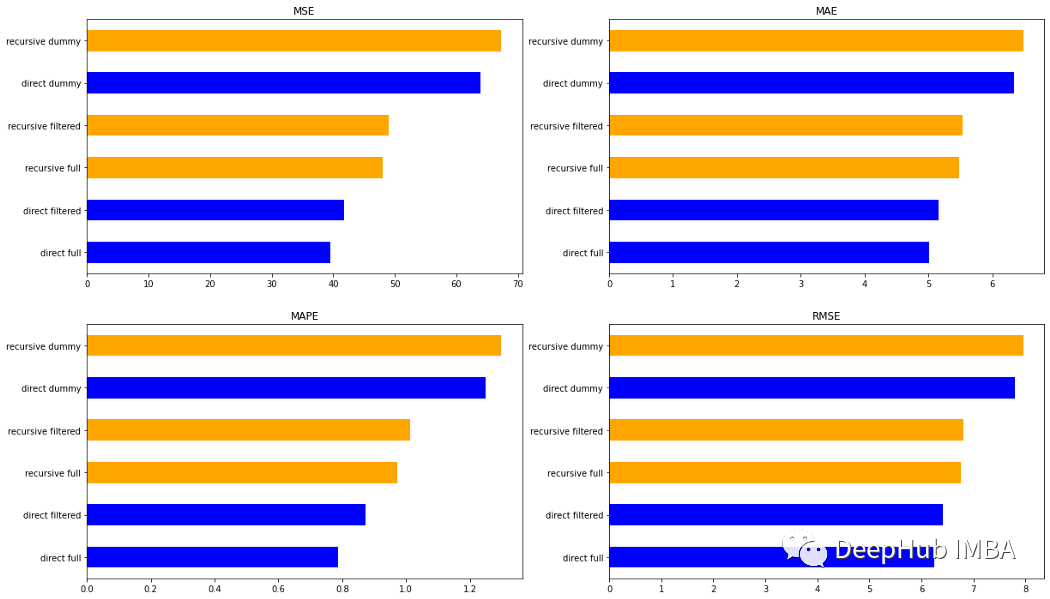
You can see that the most direct way is the most accurate. The way of Full is better than the method of Dummy and Filter. In the recursive methods, the results of Full and Filtered are almost the same.
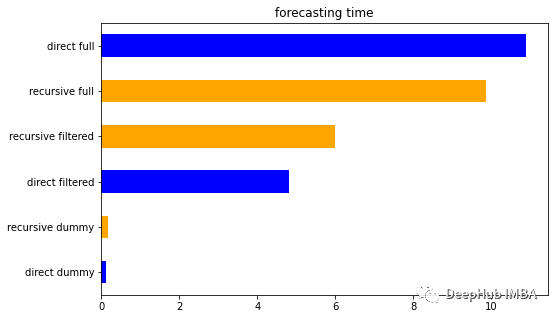
For time, the Dummy method is the fastest way. This should be expected because it considers a small number of features. For the same reason, Filtemted is faster than FULL. But surprisingly, the speed of filed is half of the Full method. This may be a good result, because we can obtain good predictions in a faster way through simple features.
The test results and tables above are treated and generated by TSPIRAL. It simplifies the recognition of meaningful self -regression lag, and gives the possibility of choice of time sequence operation feature selection. In the end, we also discovered how to reduce the reasoning time of prediction through this experiment.
If you are interested in the results of this article, please check the source code of this article:
https://github.com/cerlymarco/medium_notebook/blob/master/timeSeries_featureselect/timeSeries_featureSeleset.ipynb Edit: Yu Tengkai Kaikai Kaikai Kaikai Kaikai
- END -
How does the National Land Day 丨 rice and soil formed?

Although this sentence seems to be reasonable, it seems that the important impact ...
For the interest of interest, he "gets deeper and deeper"

Text | China Science News reporter Zhao GuangliSome people say that the fastest way...