Is CNN a local Self-ATENTION?
Author:Data School Thu Time:2022.09.14

Source: deep learning enthusiast
This article is about 2400 words, it is recommended to read for 6 minutes
Let's distinguish what CNN and Attention are doing in this article.
Is CNN a local Self-ATENTION?
CNN is not a local attention, so let's distinguish what CNN and Attention are doing.
1: CNN can be understood as a local orderly FC layer with power sharing, so CNN has two characteristics that are fundamentally different from the FC layer. That is, it is greatly reduced without losing some fundamental Feature.
2: The steps of Attention are to obtain Attention MaritX by multiplied by Q and K and indicate the similarity of the two, that is, the greater the point of the Q and K similarity. V, the result after getting attention.
The essence of Attention is to find the similarity of Q and K, emphasizing the similar part of Q and K in Q.
The essence of its essence can also be understood as CNN is extraction features. Attention can be emphasized, and the two are not similar. If all the modes are doing something around Feature, then these are obviously unreasonable words.
Update, because I have a new understanding of CNN, I update the previous answers, but my previous answer will not be deleted. What will be added in this regard? collect.
Regarding the difference between RNN and Self-Wention, you can see my answer, I hope it will be helpful to you.
https://zhuanlan.zhihu.com/p/360374591
First of all, to conclude that CNN can be regarded as a simplified version of the Self-Paytention, or the Self-O cantention is the generalization of CNN.

Previously, we compared CNN and Self-ATENTION. In fact, the subconscious thought was that CNN was used for image processing, and the Self-FTENTION was used for NLP, so there will In terms of image processing, discuss the differences and connections between CNN and Self-ATENTION, and better compare CNN and Self-FTENTION. Self-ATENTION is used for image processing:
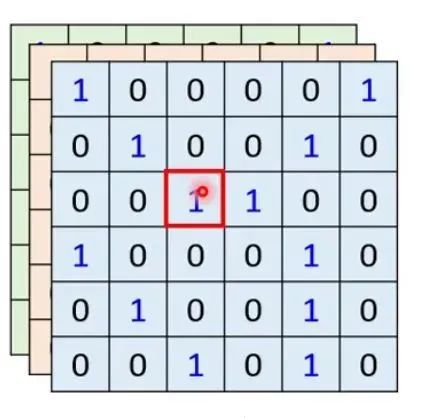
首先,如果用self-attention对图像进行处理,对于每一个pixel(像素值)产生Query,其他的pixel产生Key,Query*Key,然后softmax(正如评论中说的,其实不一定非要softmax,也You can use activated functions such as RELU), and finally use the corresponding value and seek harmony as each Pixel to pass the output value of SoftMax. Here we will find that every Pixel considers the entire picture of the entire picture when doing Self-ATTENTION, and consider all the information in the entire image.
So, if we use CNN to process images, we will choose different convolution kernels and process the image with convolution kernels. Each Pixel (pixel value) actually only needs to consider other Pixel in this convolution nucleus. You only need to consider this Receptive Field, without the need to consider all the information in the whole image.
Furthermore, we can get a general conclusion. CNN can be regarded as a simplified version of the Self-FTENTION, that is, CNN only needs to consider the information in the Receptive Field Information.
On the other hand, we can also understand that Self-ATENTION is a complicated CNN. CNN needs to delineate Receptive Field. Only the information in Receptive Field, and the range and size of the Receptive Field requires the size of itself. For Self-ATENTION, finding related pixels with Attention is as if Receptive is automatically learned, that is, this pixel is the center. Which other Pixel requires me to consider this Pixel and is related to my pixel.
In a simple word, each Pixel only learns the information in the convolution kernel, and the information in the whole image of Self-ATENTION learns in the whole image of Pixel. (Only one layer of convolution is considered here. If multi-layer convolution, CNN actually achieves similar effects as Self-FTENTION)
So, what can we get to know about Self-ATENTION and CNN?
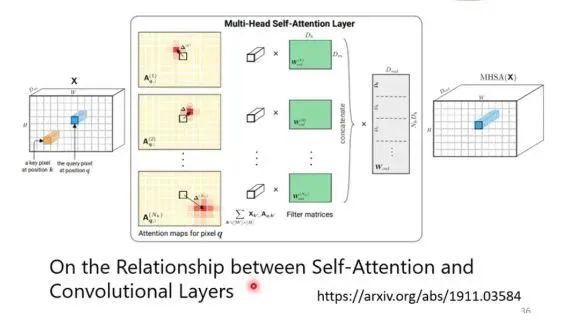
We know that CNN is a special case of Self-ATATENTION, or Self-ATATENTION is the generalization of CNN, very Flexible CNN, and do some restrictions on Self-Option. Self-ATENTION and CNN are the same. (Thesis: https://arxiv.org/abs/1911.03584 conclusions) For Self-Ftenion, this is a very Flexible model, so more data is required for training. If the data is not enough, it may may Over-Fitting, but for CNN, because of more restrictions, when there are not many Training Data, you can have a better model.
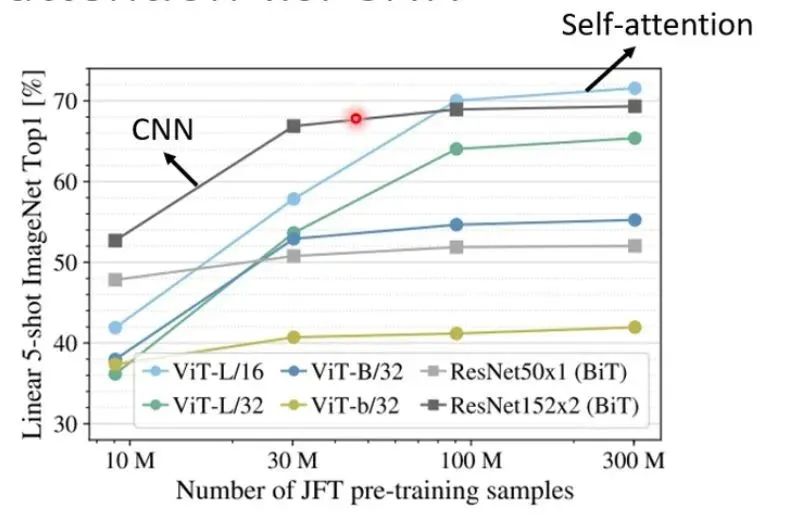
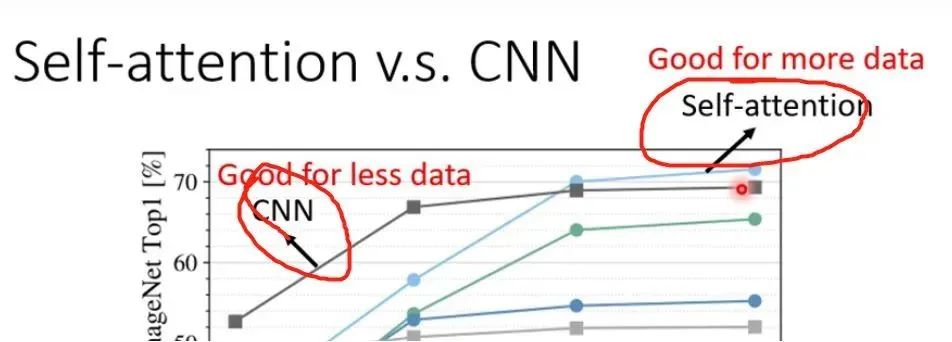
As shown in the figure, when the Training Data is relatively small, CNN is better. When the Training Data is relatively large, the effect of the Self-ATENTION will be better. That is, the elasticity of the Self-ATENTION is relatively large, so more Training Data is needed. When the training materials are relatively small, it is easy to over-fitting. The elasticity of CNN is relatively small. When there are more training data, CNN has no way to get benefits from a large amount of training materials.
Author: anonymous user
https://www.zhihu.com/question/448924025/answer/1784363556
There is similarity, but there are differences. CNN can be considered to be internal accumulation in each position and a fixed static template, which is a local projection, and Attention is calculated between different positions. In a sense In fact, it is defined as a Distance Metric. In a more common sense, CNN is more local. Self-FTENTION more emphasizes Relation. CNN is a special degeneration attention. It may be more suitable.
Author: Lin Jianhua
https://www.zhihu.com/question/448924025/answer/1793085963
I think CNN's convolutional layer and tempition are not the same thing. The K and Q of the Self-ATENTION are generated by data, so it reflects the relationship within the data.
The CNN convolutional layer can be regarded as K and Q of different data composed of parameters, reflecting the relationship between data and parameters.
In other words, the Self-Wention builds different spaces through parameters, so that the data shows different autocorrelation in different spaces.
The CNN convolution has constructed certain fixed features through the parameters, and processes the subsequent processing through the performance of statistical data in these characteristics.
Author: Aliang
https://www.zhihu.com/question/448924025/answer/1786277036
The core of CNN is to obtain global characteristics with local characteristics. It can be said that each time it focuses on a local convolution core. Finally, the overall characteristics are formed through the characteristics of local convolution kernels.
The self -attention mechanism is to focus on its own self, and it is calculated by itself. Its advantage is that through the self -attention mechanism, it can be able to integrate into the global information through the self -attention mechanism. Essence
Therefore, CNN is partial to the whole, and the self -attention mechanism is the overall auxiliary part. If you have to get CNN with attention, I personally understand that it can be regarded as a local attention (pay attention to no self -word)
Author: aluea
https://www.zhihu.com/question/448924025/answer/179309914
Turning the order, Self-ATENTION is a CNN that is strongly invacuated.
This is not difficult to understand, let's take a look at what Self-ATENTION has done.
Assuming, for a layer of Self-ATENTION, there are four types of features in A, B, C, and D, which can be entered at the same time, and the embedded of only AC and BD Combine indicates contributions to the downstream tasks. Then Self-ATENTION will pay attention to these two Combine and cover up other features; for example, [a, b, c]-& [a ', 0, c']. Ps. A 'represents the output representation of A.
For a layer of CNN, it is relatively straightforward.Then CNN can complete the function like Self-ATENTION. It is entirely possible. Add a layer of CNN to make two filters and a filter AC; one filter BD is over.Of course, my CNN can not do so, and it can fit the distribution; and the self-teeth must do so, so this is a stronger induction bias.
Regarding the importance of indisting bias, I won't go into details here.
Author: MOF.II
https://www.zhihu.com/question/448924025/answer/1797006034
CNN is not a local Self-ATATENTION, but it can be implemented by the local self-teeth into a layer. The method of doing the whole Self-FTENTION network can be realized. Refer to the Stand-Alone Self-Osion In Vision Models of the Google Brain in Neurips19.
The second section of the article compares the calculation method of the convolutional layer and the Self-ATENTIN layer, which is worth seeing.
Edit: Wang Jing
- END -
It can make Excel Xiaobai tall, just remember these four shortcut keys, easy to learn and easy to learn

Hello everyone, I am nothing more than a teacher. Today I want to talk to you abou...
2022, discovered the beauty of Chinese soldiers

Today is the 7th year of the 7th year of the sky with yousomeone saidEach Chinese ...