Original | One article understands bert source code
Author:Data School Thu Time:2022.09.12

Text: Chen Zhiyan
This article is about 4400 words. It is recommended to read 10+ minutes
In this article, the source code of the BERT model pre -training task is interpreted in detail. In the Eclipse development environment, the implementation steps of the Bert source code are analyzed step by step.
The Bert model architecture is a coder architecture based on a multi -layer two -way transform (Transformers), which is released under the Tensor2TENSOR library framework. Because the Transformers are used in the implementation process, the implementation of the Bert model is almost the same as Transformers.
The Bert pre -training model does not use the traditional one -way language model from left to right or from right to left for pre -training. Instead, pre -training uses a two -way language model from left to right and right. The source code of the pre -training task is interpreted in detail. In the Eclipse development environment, the implementation steps of the Bert source code will be parsed step by step.
The size of the Bert model is relatively large. Due to space limitations, it is impossible to explain each line of code. Here, explain the functions of each of the core modules.
1) Data reading module
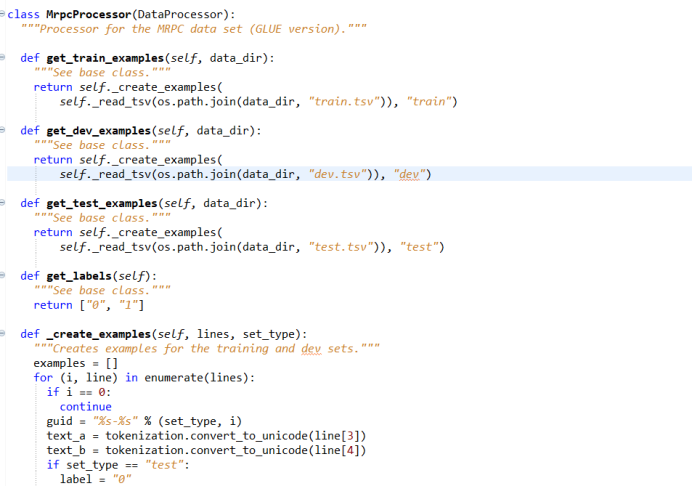
figure 1
The first step of model training is to read data, read the data from the data set, and then process the data according to the data format required by the Bert model, write the class processing of specific data processing The method of data processing, if the dataset used in the task is not MRPC, the code of this part needs to re -write the code of how to operate the data set according to a specific task. For different tasks Read the data and line.
2) Data pre -processing module
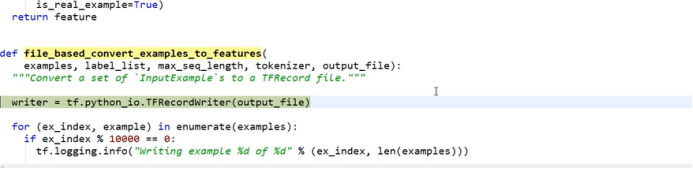
figure 2
Use TensorFlow to pre-process the data. Because the data reads data is relatively fast and it is more convenient to use it. At the data reading level, the data needs to be converted to TF-recorder format. First of all, define a Writer, and use the Writer function to write the data sample into TF-record. In this way, in the process of practical training, you do n’t have to read the data every time. Take the processing data.
The specific practice of turning each data sample into a TF-record format is as follows: First, build a label, and make a judgment of the data. The judgment of the data consists of a few sentences. After getting the current first sentence, after getting the current first sentence,, after getting the current first sentence,, after getting the current first sentence, the current first sentence is obtained. Do a word split operation. The word split method is the wordpiece method. In the English text, the words consisting of words, words and words using spaces to cut the words, using spaces to divide the words often insufficient. The input words are further divided, and the greedy matching method of Wordpiece is used to further divide the input words into words, so that the meaning of the word expression is richer. Here, use the WordPiece method to cut the reading words again, and cut the input word sequence into a more basic unit, so as to be more convenient for model learning.
In the Chinese system, usually cut the sentence into a single word. After the division is completed, the input is converted into WordPiece structure with wordpiece, and then a judgment to see if there is a second sentence input. If there is a second sentence input, input Then use Wordpiece to do the same process of the second sentence. After the wordpiece conversion is done, make another judgment to determine whether the length of the actual sentence exceeds the value of max_seq_length. If the length of the input sentence exceeds the value specified by MAX_SEQ_LENGTH, it needs to be cut off.
3) TF-record production
Code the input sentence, traverse each word of Wordpiece structure and Type_id of each word, add a sentence separator CLS, SEP, add encoding information to all results; add Type_ID, mapping all the words for the input word to the input words The ID (identifier) is encoded to facilitate the search when the subsequent words are embedded;
MASK coding: Sentences less than max_seq_length to make a complement operation.在self_attention 的计算中,只考虑句子中实际有的单词,对输入序列做input_mask 操作,对于不足128个单词的位置加入额外的mask,目的是让self_attention知道,只对所有实际的单词做计算,在In the subsequent Self_attention calculation, the words of input_mask = 0 are ignored, and only the words of input_mask = 1 will actually participate in the self_attention calculation. Mask encoding initializes the subsequent fine -tuning operations, and realizes the pre -processing of task data.
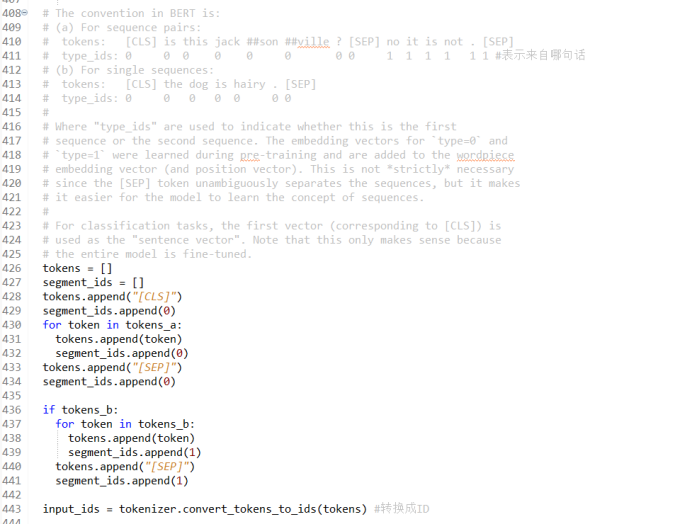
image 3
Be initialized to input_feature: build input_feature and return the results to Bert. Through a FOR loop, you traverse each sample, and then make some processing, and convert the INPUT_ID, Input_Mask and Segment_id into an INT type, which is convenient for subsequent TF-Record to make. The reason why data types are made is because TensorFlow's official API requires this. TensorFlow has made a hard rule on the format of TF-record, and users cannot modify them by themselves. In the subsequent specific project tasks, when doing TF-Record, just copy the original code in the past and modify it according to the original format. After constructing Input_feature, pass it to tf_example and convert it to tf_train_features. After that, write it directly into the constructed data. 4) The role of the Embeding layer
There is a Creat_model function in the BERT model that builds the model step by step in the Creat_model function. First, create a Bert model, which contains all the structures of Transformer. The specific operation process is as follows:
Figure 4
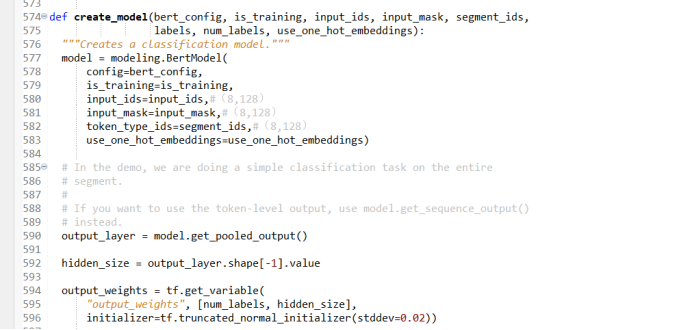
Read the configuration file to determine whether you need to train, read the variables such as input_id, input_mask, and segment_id. One_hot_embedding variables are used when using TPU training. You do n’t need to consider when using CPU training. The default value is set to Faulse.
Construct the Embedding layer, the word embedded, and the word embedding operation will convert the current sequence into a vector. Bert's Embedding layer not only considers the input word sequence, but also needs to consider other additional information and location information. The word embedded vector built by Bert contains the following three information: that is, input word sequence information, other additional information and location information. In order to achieve the calculation between vector, the dimensions of the word vector containing these three information must be maintained.
5) Add extra coding features
Next, enter the Embedding_Lookup layer. The input of this layer is: input_id (input identifier), vocab_size The output of Embedding_Lookup is an actual vector encoding.
Figure 5

First, get Embedding_table, and then find the word vector corresponding to each word in Embedding_table, and return the final result to Output. In this way, the input words become a word vector. But this operation is only part of the word embedding. The complete word embedded should also add other additional information to the word embedding, that is, the Embedding_POST_PROCESSOR.
embedding_post_processor是词嵌入操作必须添加进去的第二部分信息,embedding_post_processor的输入有:input_tensor、use_token_type、token_type_id、token_type_vocab_size,返回的特征向量将包含这些额外的信息,其维度和输入单词的词向量一致。
6) Add position encoding features
Use USE_POSITION_EMBEDDING to add position encoding information. BERT's Self_attention needs to add position encoding information. First, use the full_position_embedding to initialize the position to add the location of each word to embed the vector to the word vector. Code these 128 positions. Because the position code contains only location information, it has nothing to do with the context of the sentence. For different input sequences, although the content of the input sequence is different, their position encoding is the same, so the results of the position coding results and the actual actual actual situation What words in the sentence have nothing to do, regardless of the content of the data, their location codes are the same. After obtaining the output result of the position coding, based on the original word embedded output vector, plus the additional characteristic vector and location coding vector obtained by the additional coding, the three vectors are found, returned to the result and the result. The input words are embedded to get a word vector containing location information. Next, in -depth operation of this vector.
Image 6

7) MASK mechanism
After completing the word embedding, the next step is the Transformer structure. Before transformer, you must make some conversion to the word vector, that is, attention_mask, create a Mask matrix: create_attention_mask_from_input_mask. In the INPUT_MASK mentioned earlier, only the words of Mask = 1 are involved in the calculation of Attention. Now you need to convert this two -dimensional Mask into a three -dimensional Mask, indicating that when the word vector enters Attention, which vector will participate in the participation In the actual calculation process. That is, when calculating the Attention, which words of the 128 words in the input sequence are calculated, and here, an additional Mask processing operation is added. Figure 7
After completing the Mask processing, the next is the Encode side of the TRANSFORMER. First, some parameters are passed to Transformer, such as: input_TENSOR, Attention_Mask, Hiden_Size, Head_num, and so on. These parameters have been set during the pre -training process, and these parameters must not be changed at will during fine -tuning operations.

In the long -headed Attention mechanism, each head generates a feature vector, and eventually splices the vectors generated by each head together to get the output feature vector.
8) Build a QKV matrix
Next is the implementation of the Attention mechanism. The Attention mechanism of the Bert is a multi -layer architecture. In the specific implementation of the program, the traversal operation is used to achieve multi -layer stacks by traversing each layer. A total of 12 layers need to be traversed, and the input of the current layer is the output of the previous layer. In the Attention mechanism, there are two inputs: from-Tensor and To_Tensor, and the Attention mechanism of the Berton uses Self_attention. At this time:
From-Tensor = To_TENSOR = layer_input;
Figure 8
In the process of constructing the Attention_layer, the three matrices of K, Q, and V need to be constructed. K, Q, and V matrix are the core parts in transformr. When constructing the K, Q, V matrix, the following thumbnails will be used:

B represents the typical value of the batch of Batch Size, which is 8 here;
F represents the FROM-TENSOR dimension is 128;
T represents TO_TENSOR dimension 128;
N Number of Attention Head Attention (Multi -ATTENTION Mechanism) is a typical value here for 12 heads;
H size_per_head represents how many characteristic vectors of each head, and the typical value here is 64;
Build the Query matrix: build the Query_layer query matrix, the query matrix is built by the from-Tensor. In the longitation Attention mechanism, how many Attention heads are generated, and how many Query matrix is generated.
query_layer = b*f, n*h, that is 1024*768;
Figure 9
Constructing the key matrix: The KEY matrix is built from To-Tensor. In the long-headed Attention mechanism, how many Attention heads are generated, and how many key matrix is generated.

key_layer = b*t, n*h, that is 1024*768;
Figure 10
Building Value matrix: The construction of the value matrix is basically the same as the construction of the key matrix, but the description is different:

Value_layer = b*t, n*h, that is, 1024*768;
After the QKV matrix is completed, calculate the inner accumulation of the K matrix and Q matrix, and then perform a SoftMax operation. Through the Value matrix, we help us understand what the actual characteristics are. The Value matrix and the key matrix completely correspond to the exactly the same.
Figure 11
9) Complete the TRANSFORMER module construction

After the completion of the QKV matrix, next, you need to calculate the inner accumulation of the K matrix and Q matrix. In order to accelerate the calculation of the inner accumulation, a transpose conversion is made here to accelerate the calculation of the inner accumulation, which does not affect the subsequent operations. Essence After calculating the internal accumulation of the K matrix and Q matrix, the value of Attention was obtained: Attention_score, and finally need to use the SoftMax operation to convert the points of the obtained attention into a probability: attention_prob. Before doing SOFTMAX operations, in order to reduce the calculation amount, you need to add Attention_Mask to block the sequence of 128, not the actual word is shielded, and not allow them to participate in the calculation. There is a ready -made SoftMax function in TensorFlow to call it, and pass all the current Attention scores to SoftMax. The result is a probability value. Attention_prob and the value matrix are performed by multiplication, and the context matrix is obtained, that is:
context_layer = tf.matmul (attentation_prob, value_layer);
Figure 12
After getting the current semantic matrix output, this output is used as the input of the next layer to participate in the calculation of the next layer of Attention. Multi -layer Attention is achieved through multiple iterations of a for loop. It is 12 layers) how many layers of iteration calculations are performed.
10) Training bert model

After finishing the seld_attention, the next is a full connection layer. Here, the full connection layer needs During the implementation process, the final result needs to be returned. The output result of the last layer is returned to Bert, which is the structure of the entire transformer.
Figure 13
To sum up the above process, that is, the implementation of Transformer is mainly divided into two parts: the first part is the Embedding layer. The second part is to send the output vector of the Embedding layer into the Transformer structure. By constructing three matrix three matrix K, Q, and V, the SoftMax function is used to obtain the above semantic matrix C. The encoding feature also includes the location encoding information of each word.
This is the implementation of the Bert model. It understands the detailed process of the above two parts. There is no big problem with the understanding of the BERT model. The above ten steps basically cover important operations in the Bert model.
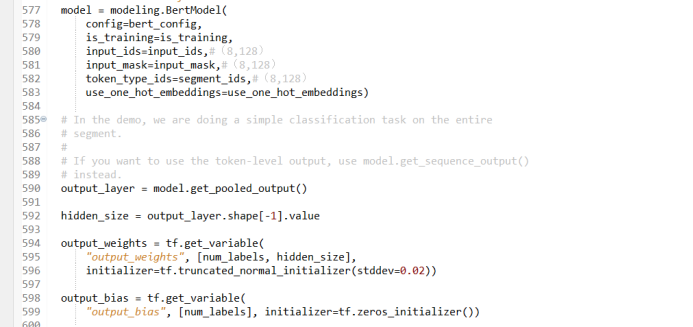
After the BERT model, the final obtaining a feature vector, this feature vector represents the final result. The above is the entire process of the open source MRPC project officially announced by Google. When readers build their own specific tasks, they need to modify how to read some code of the data into the Bert model to achieve data pre -processing.
Edit: Huang Jiyan
- END -
Lei Jun traversed through the trough of life three times, what about Xiaomi?

Economic Observation Network reporter Qian Yujuan At 7 pm on August 11, Mr. Lei ga...
After the three -wheeled inquiry of European Technology, IPOs have been conference: R & D cost rate is 0.4%, and more than 60%of the income rely on Amazon

Picture source: Oriental ICA few days ago, the results of the 41st review meeting ...