ECCV 2022 | CMU proposes the first visual framework for fast knowledge distillation: resnet50 80.1%accuracy, training acceleration 30%
Author:Data School Thu Time:2022.09.04

Source: Heart of the machine
This article is about 4500 words, it is recommended to read for 9 minutes
Today, an article from ECCV 2022 from Katiki Mellon University and other units on fast knowledge distillation.
Today, an article from ECCV 2022 from Kanegi Mellon University and other units, an article on fast knowledge distillation. Use basic training parameter configuration to train ResNet-50 in ImageNet-1K from the beginning (from scratch) to 80.1% ( Data not to use Mixup, Cutmix and other data enhancement), training speed (especially data reading overhead) saves more than 16% compared to the traditional classification framework, which is more than 30% faster than the previous SOTA algorithm. It is the best knowledge distillation of the current accuracy and speed. One of the strategies is that the code and model are all open source!

Thesis and project website:
http://zhiqiangshen.com/projects/fkd/index.html
Code:
https://github.com/szq0214/fkd
Knowledge distillation (KD) has been proposed by Geoffrey Hinton and others in 2015, and has had a huge impact in the fields of model compression, visual classification detection and other fields. In the future, countless related variants and extended versions have been produced, but the following categories can be divided into several categories: Vanilla KD, Online KD, Teacher-Free KD, etc. Recently, many studies have shown that the simplest and simple knowledge distillation strategy can achieve huge performance improvement, and the accuracy is even higher than many complex KD algorithms. But Vanilla KD has an inevitable disadvantage: each time you need to enter the training sample into Teacher, the soft label (Soft Label) is produced, which causes a large part of the calculation overhead to traverse the Teacher model. However The scale is usually much larger than the Student. At the same time, the weight of the Teacher is fixed during the training process, which causes the learning efficiency of the entire knowledge distillation framework to learn very low.
In response to this problem, this article first analyzes why it can generate a single soft label vector directly for each input image and then reuse this label during different Iterations training processes. The root cause is Random-Resize-Cropping this image enhancement strategy, resulting in the input sample generated by different ITERATION, even if it comes from the same picture, it may come from the sampling of different areas, resulting in the sample and a single soft label vector that cannot be well matched well in different ITicals. Based on this, this article proposes a designs of rapid knowledge distillation, which process the required parameters through specific coding methods, and then further store the reuse of soft label (Soft Label). Essence Through this strategy, the entire training process can be explicit-free, which is characterized by this method (16%/30% of training acceleration, which is particularly friendly for the slow disadvantages of data reading on the cluster). (Use ResNet-50 to not use additional data enhancement on ImageNet-1K to reach 80.1% accuracy).
First of all, let's review how ordinary knowledge distillation structure works, as shown in the figure below:
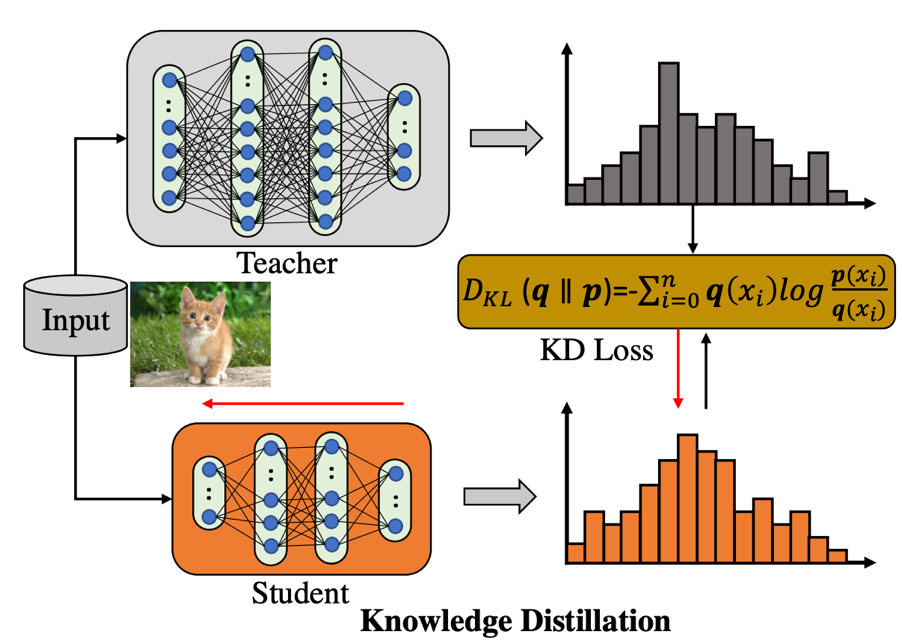
The knowledge distillation framework contains a pre -trained Teacher model (fixed weight of the distillation process), and a Student model to be learned. Teacher is used to produce Soft's Label to monitor Student learning. It can be seen that there is a relatively obvious disadvantage in this framework: when the Teacher structure is greater than the Student, the calculation overhead generated by training images has exceeded the Student. It is "useless". The motivation of this article is to avoid or repeatedly use this additional calculation results in the process of knowledge distillation training. At the same time, the training process is trained at the same time. So the question becomes: how does Soft Label organize and store the most effective? Let's look at the strategy proposed in this article.
1. FKD algorithm framework introduction
The core part of the FKD framework contains two stages, as shown in the figure below: (1) the generation and storage of soft labels (2) using Soft Label for model training with Soft Label.
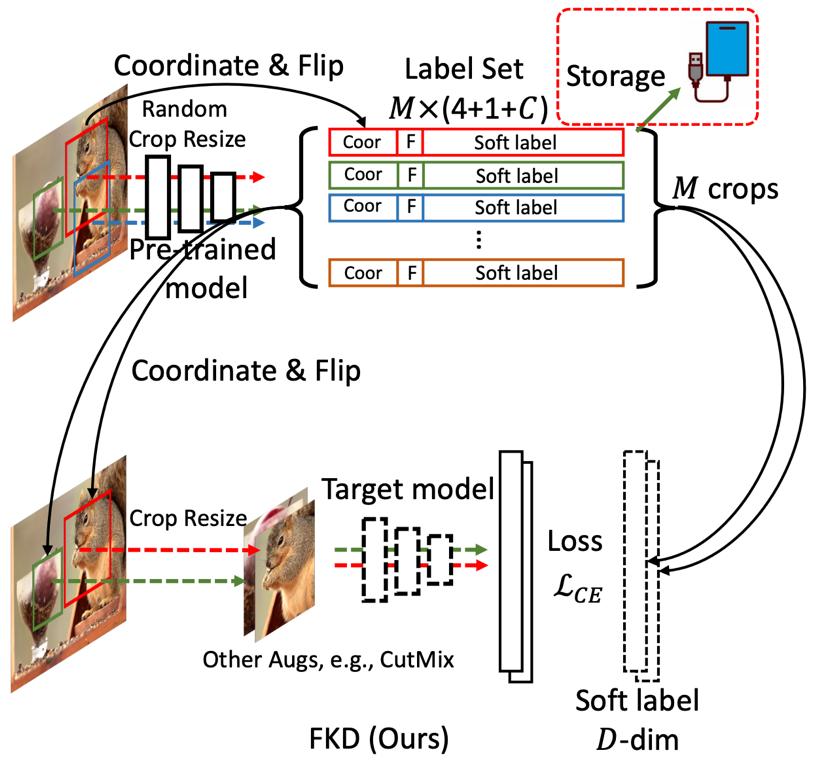
As shown in the figure, the first half shows the production process of soft labels. The author enters multiple CROPS into the pre -trained Teacher to generate the required soft label vector. At the same time Coordinates and (2) whether to flip the Boolean value. The second half shows the Student training process. When the author also reads their corresponding soft label files when random samples, nn CROPS is selected for training. Elimination of additional data, such as mixup, CUTMIX will be placed at this stage. As a result, additional storage overhead caused by introducing more data enhancement parameters. 2. Sample strategy
This article also proposes a Multi-Crop Sampling strategy, that is, each picture of multiple samples in a mini-batch. When the total training EPOCHS does not change, the sampling method can greatly reduce the number of data reading. For some cluster equipment that is not very efficient or generates serious bottlenecks, the acceleration effect of this strategy is very obvious (as shown in the following form (as the following form is the table below Show). At the same time, multiple CROPS samples can reduce the variance between training samples and help stable training. The author finds that if the number of CROPS is not too large, the model accuracy can be significantly improved, but the number of CROPS in the picture will be sampled too much. Causes that the information differences in each mini-batch are insufficient (too similar), so excessive sampling will affect performance, so a reasonable value is needed.
3. Acceleration ratio
The author compared with the standard training method and standard training method and the standard training method. The result is as shown in the following form: it can be seen that compared with the normal classification framework, FKD will be about 16% faster, while RELABEL is 30 faster 30 faster. %, Because Relabel needs to read double the number of files than normal training. It should be noted that in this speed comparison experiment, the number of FKD CROP is 4. If you choose a larger number of CROP, you can get a higher acceleration ratio.
Analysis of the cause of acceleration:
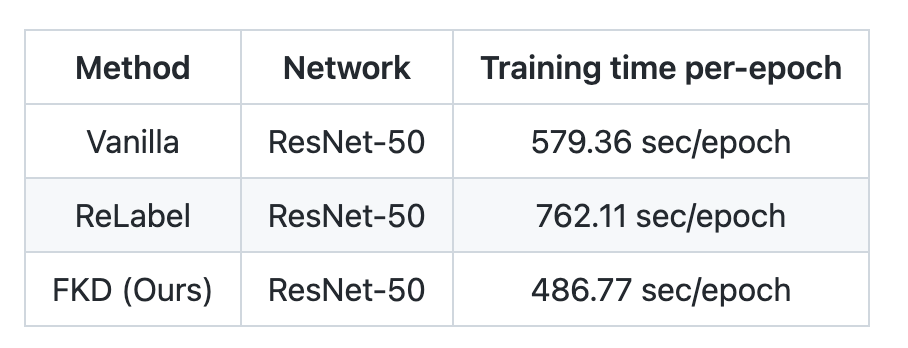
In addition to the above-mentioned introductions to accelerate, the author also analyzes other acceleration factors, as shown in the figure below, Relabel needs to generate the coordinates of sampling data during the training model stage. At the same time, ROI-Align and Softmax need to generate In contrast, the required soft labels, FKD directly preserves the coordinate information and the final soft label format, so you can train directly after reading the label file. Essence
4. Label quality analysis
The quality of soft label is the most important indicator to ensure the accuracy of model training. The author proves that the proposed way to propose a better soft label quality is proved through the visual label distribution and calculating the cross-entropy (Cross-Entropy) between different model predictions. Essence
The above figure shows the comparison of the distribution of FKD and Relabel soft labels. The following conclusions are obtained:
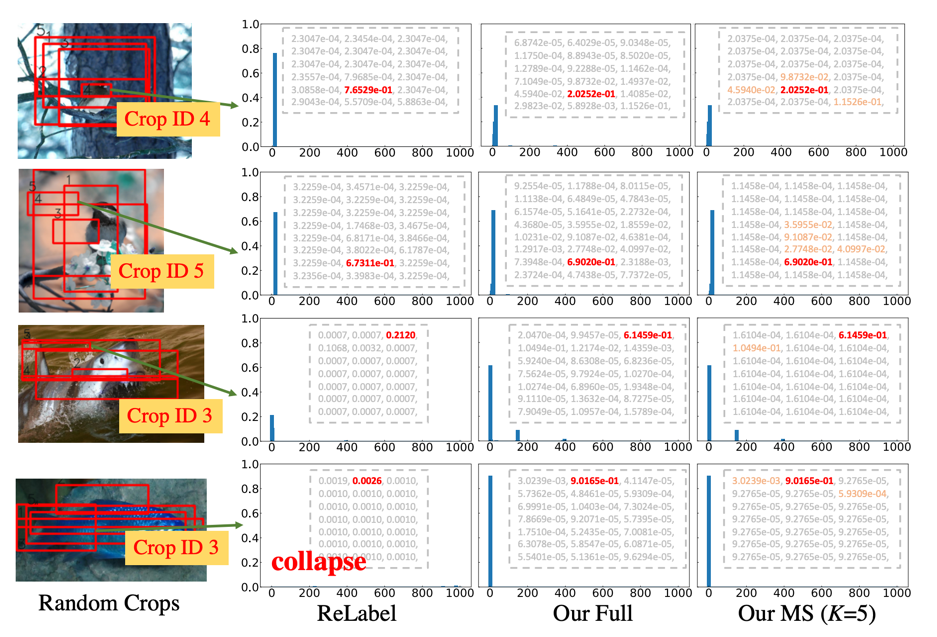
(First line) FKD is more confident than RELABEL's confidence, and it is more consistent with the content of the input sample. The author's analysis is that Relabel enters the global image into the model instead of the local area. The global category information ignores the background information at the same time, so that the generated soft label is too close to a single semantic label.
(Line 2) Although there are some samples of the maximum prediction probability of some samples Relabel and FKD, FKD contains more subordinate categories in the label distribution, and the distribution of Relabel does not capture the information of these subordinate categories.
(Third line) For some abnormalities, FKD is more robust than Relabel, such as the target box contains loose boundaries, or only locate some targets.
(Fourth line) In some cases, the label distribution of Relabel is unexpectedly collapsed (evenly distributed), without producing a major prediction, and FKD can still predict well.
5. Label compression and quantification strategy
1) Hardening. In this strategy, the sample label Y_h uses the largest LOGITs index predicted by Teacher. The label sclerosis strategy still produces the label of One-HOT, as shown in the following formula:
2) Smoothing. The smooth quantitative strategy is to replace the above -mentioned hardening tag y_h to a combination of segmented function with soft labels and uniform distribution, as shown below:
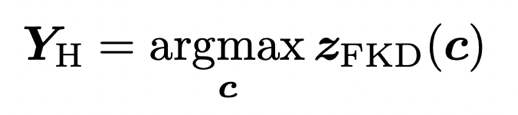
3) Marginal Smoothing with Top-K. The marginal smooth quantification strategy retains more marginal information (TOP-K) than a single prediction value to smooth label Y_S:
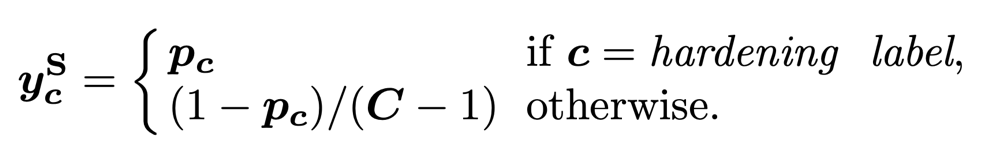
4) Marginal Re-Norm with Top-K. The marginal smooth kettle strategy will return the TOP-K predictive value to the harmony to 1, and maintain the value of other elemental values (FKD uses normalization to calibrate the sum of the TOP-K predictive value as 1, because FKD storage The soft label is the value after SoftMax processing): The icon of the specific quantitative strategy above the above is shown in the figure below:
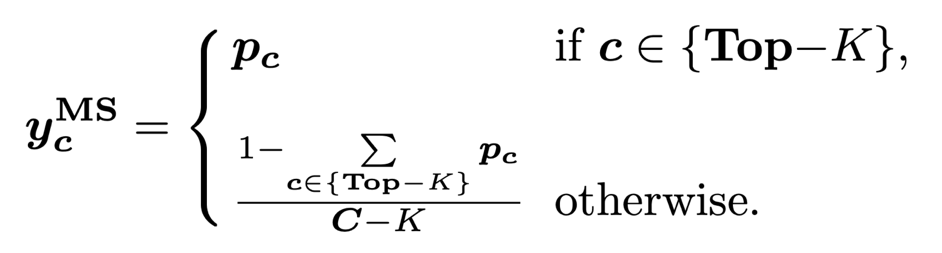
6. Comparison of storage size of different labels / compression strategies
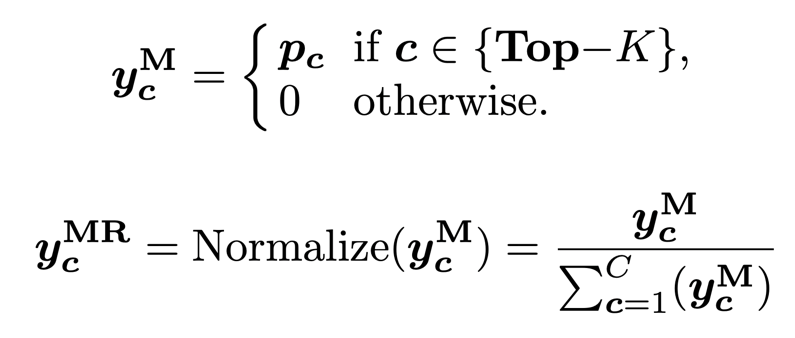
The storage space required by different label compression methods is as shown in the following form. The data set used is ImageNet-1K. Among them, M is the number of each image sampled in the soft label generation stage. Here the author selected 200 as an example. NIM is the number of images, the ImageNet-1K dataset is 1.2m, SLM is the size of the RELABEL tag matrix, CClass is the number of classes, and DDA is the parameter dimension that requires storage data.
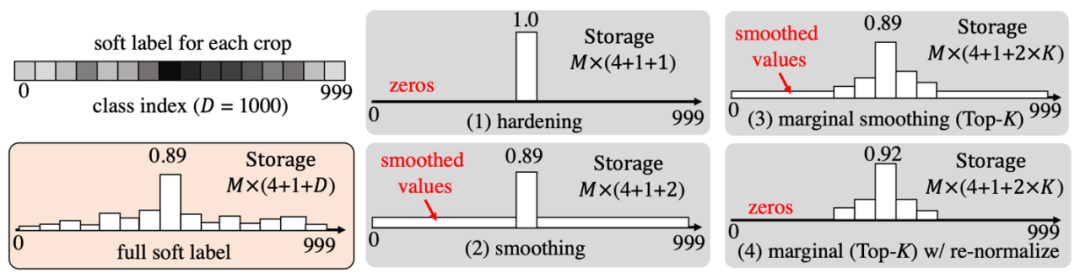
It can be seen from the table that the storage space required for FKD soft labels without any compression is 0.9T, which is obviously unrealistic in actual use. The size of the label data has far exceeded the training data itself. Compression by labeling can greatly reduce the storage size. At the same time, the experiment also proves that the appropriate compression method does not damage the model accuracy.
7. Application of self -supervision learning tasks

FKD's training method can also be applied to self -supervision and learning tasks. The author uses self -monitoring algorithms such as MOCO, SWAV, etc. to pre -training Teacher models, and then generates soft tags (UNSUPERVISED SOFT Label) for self -monitoring according to the above method. This step is similar to the Teacher obtained by supervision learning. The generating labeling process will retain the final output vector after the original self -monitoring model, and then save this vector as a soft label. After getting the soft label, you can use the same supervision method to learn the corresponding Student model.
8. Experimental results
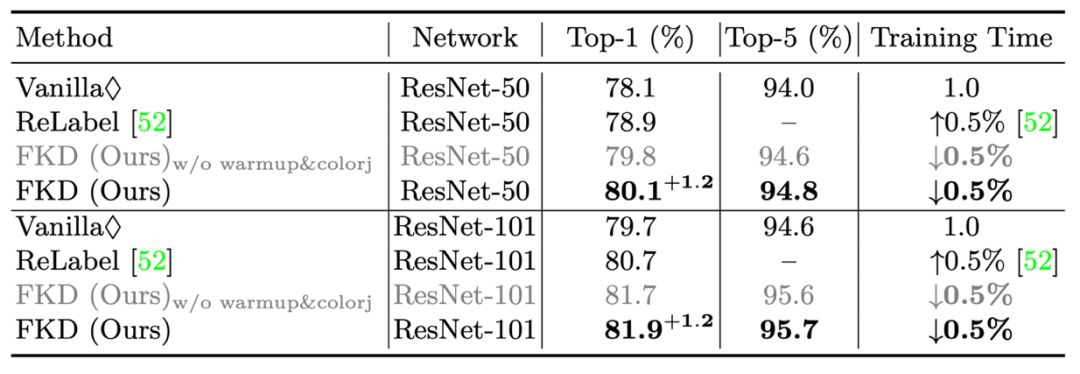
1) The first is the result of the resnet-50 and resnet-101. As shown in the table below, FKD obtained the accuracy of 80.1%/ResNet-50 and 81.9%/Resnet-101. At the same time, the training time is much faster than ordinary training and Relabel.
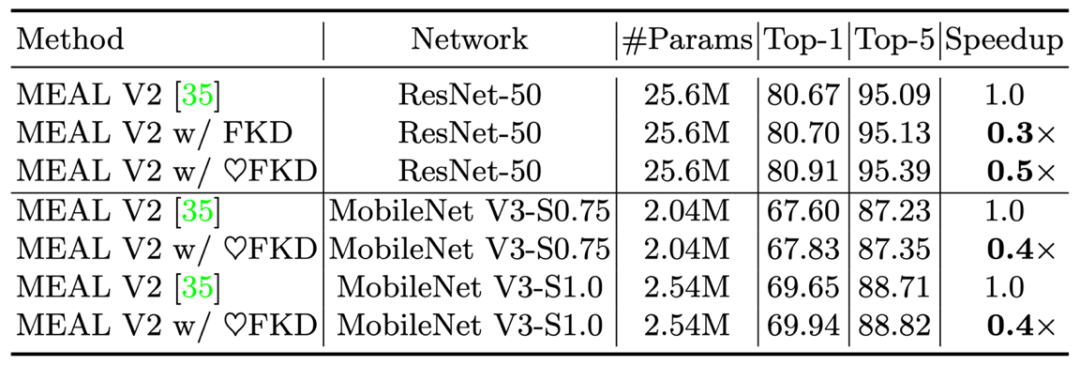
2) The author also tested the results of FKD on Meal V2, and also received 80.91% of the results.
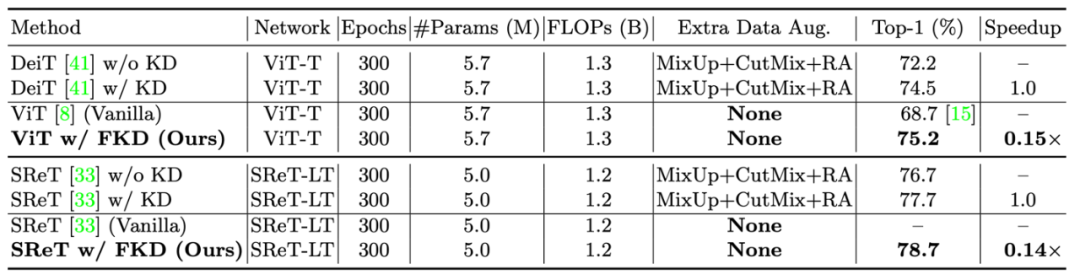
3) Results on Vision Transformer:
Next, the author shows the results on Vision Transformer. Without the use of additional data enhancement, FKD can be improved by nearly a point than the previous knowledge distillation method, and the training speed is more than 5 times faster.
4) Results on tiny cnns:
5) Fully experiment:
The first is different compression strategies, comprehensively considering storage requirements and training accuracy. The marginal smooth strategy is the best.

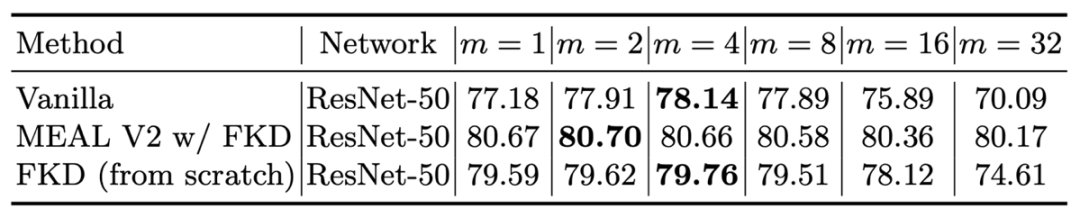
The following is the comparison of different CROP numbers during the training phase. Because the MEAL V2 uses the pre-Trained parameters as the initialization weight, the performance is relatively stable and close at different CROP numbers. Vanilla and FKD are the best when crop = 4. Especially Vanilla, compared to CROP = 1 accuracy, a point is improved, and the accuracy decreases significantly after CROP is greater than 8.
6) Results of self -supervision tasks:

As shown in the table below, the FKD method can still be a good learning target model on the self -supervising learning task. At the same time, compared with the Gemini structure self -supervising network training and distillation training, it can accelerate three to four times.
9. downstream task
The following table gives the results of the FKD model on the two data sets of ImageNet Real and ImageNetV2. It can be seen that FKD has made stable improvements on these data sets.

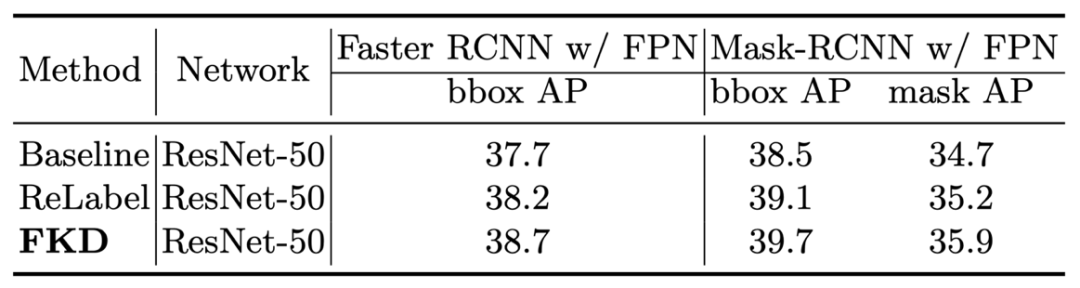
The following table is the result of the FKD pre -training model on the COCO target detection task, which is also obvious.
10. Visual analysis

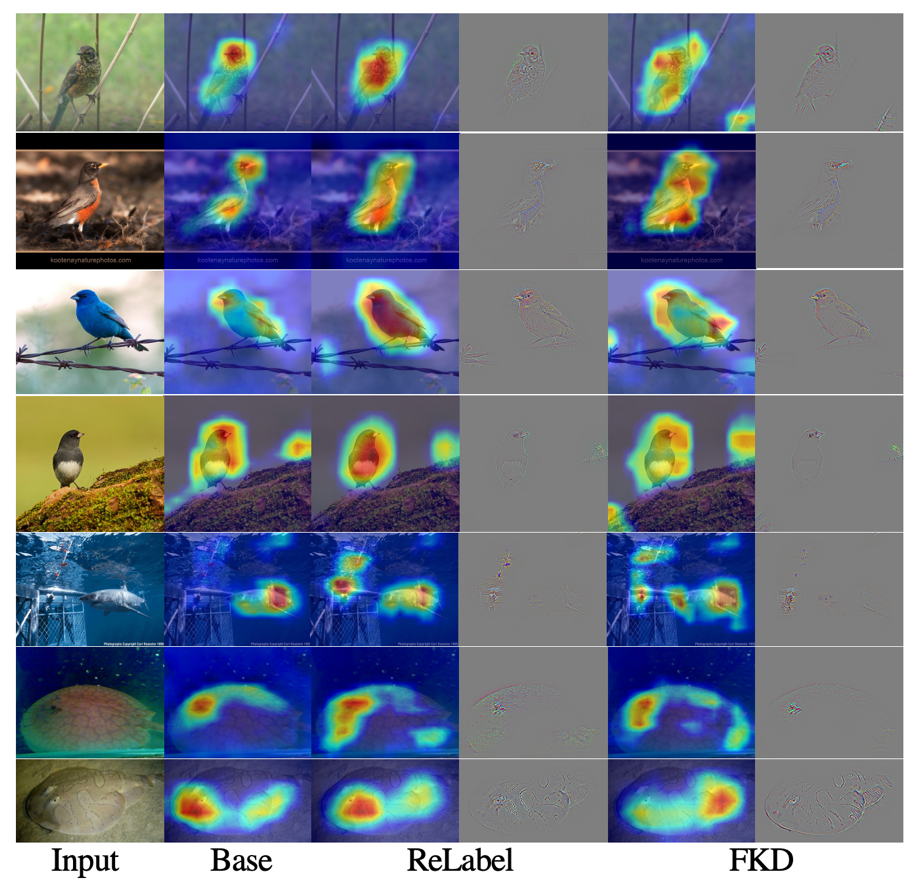
As shown in the following two visual diagrams, the author explores the effects of the recion-based training method on the model through the ATTENTION MAP. Hot Label, Relabel and FKD proposed in this article.
(I) The probability value of FKD's prediction is smaller than that of Relabel, because the context and background information introduced by the FKD training process.In the FKD random CROP training strategy, many sample samples in the background (context) area, soft prediction tags from the Teacher model can truly reflect the actual input content, and these soft labels may be completely different from the ONE-HOT tags. FKDThe training mechanism can better use additional information in the context.(Ii) FKD's feature visual diagram has a larger high response area in the object area, which indicates that the model of FKD training uses more clues to predict, thereby capturing more differential and fine -grained information.
(III) Relabel's attention visual map is closer to the PyTorch pre -training model, and the results of FKD are different from them.This shows that the attention mechanism learned by the FKD method is significantly different from the previous model. From this point, it can further study its effective reasons and working mechanisms.
Edit: Yu Tengkai

- END -
"Invisible fence" "Smart Watch" ... Digital empowerment builds a better living environment for the villain in the village

Cover News Profile Reporter Tan Yuqing picture provided by the respondentYou have ...
Central Radio and Television Terminal Zooming!The era of "eating white food" after the business audio platform is over?

Original: Li LeiThere are many infringement phenomena, high rights protection cost...