2022 latest review!One article detailed explanation of the multi -mode fusion perception algorithm in autonomous driving (data level/feature level/target level)
Author:Data School Thu Time:2022.08.14

This article is about 4,300 words, it is recommended to read for 5 minutes
From the different stage of the integration stage, the two categories of two categories and four categories of this field also analyzed the problems existing in the current field and provided a reference for the future research direction.
1 Introduction
Multi -mode sensor integration means complementary information, stability, and security, and it has long been an important part of autonomous driving perception. However, inadequate information use, noise of the original data, and misalignment between each sensor (such as the time stamps are not synchronized), these factors have caused fusion performance to be limited. This article comprehensively surveyed the existing multi -modal autonomous driving perception algorithm. The sensors include lidar and cameras, focusing on target detection and semantic segmentation, and analyzed more than 50 documents. Different from the traditional fusion algorithm classification method, this article will classify two categories and four categories in this field from the different stage. In addition, this article analyzes the problems existing in the current field and provides a reference for future research directions.
2 Why do you need multi -modal?
This is because of the inherent defects of the perception algorithm of the single -mode state [4, 26]. For example, the positioning position of the general lidar is higher than the camera [102]. In a complex real -time driving scenario, objects may be blocked in the front vision camera. At this time, the use of lidar may capture the missing target. However, due to the limitation of the mechanical structure, LIDAR has different resolutions at different distances, and is easily affected by extremely bad weather, such as heavy rain. Although both sensors can be used alone, from the perspective of the future, the complementary information of LIDAR and cameras will make autonomous driving safer on the perception level.
Recently, the multi -modal perception algorithm of autonomous driving has made great progress. technology. However, there are only a few reviews [15, 81] focusing on the methodology of multi -mode fusion, and most literature follows the traditional classification rules, that is, it is divided into three categories: front -fusion, depth (characteristics) fusion, and post -fusion. Pay attention to the stage of characterization in the algorithm, whether it is data level, feature -level or proposed level. There are two problems in this classification rules: first, there is no clear definition of the characteristics of each level; second, it handles the two branches of laser radar and camera from a symmetrical perspective, and then blurred the fusion of the characteristics of the middle -level characteristics of the LIDAR branch. The fusion of data -level characteristics in the camera branch [106]. In summary, although the traditional classification method is intuitive, it is no longer applicable to the development of multimodal integration algorithms at this stage, which hinders researchers to study and analyze from the perspective of the system to a certain extent.
3 tasks and public competitions
Common perception tasks include target detection, semantic segmentation, in -depth completion and prediction. This article focuses on detection and segmentation, such as obstacles, traffic signal lights, detection of traffic signs and lane lines, and separation of freespace. The task of autonomous driving perception is shown in the figure below:
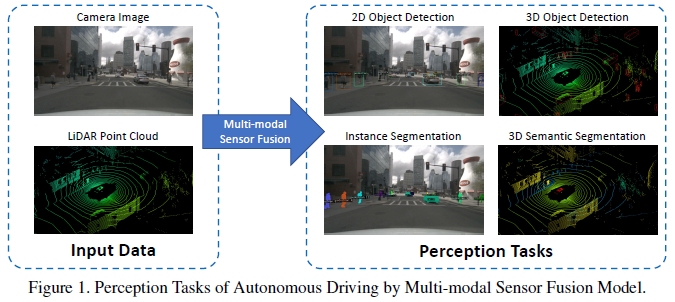
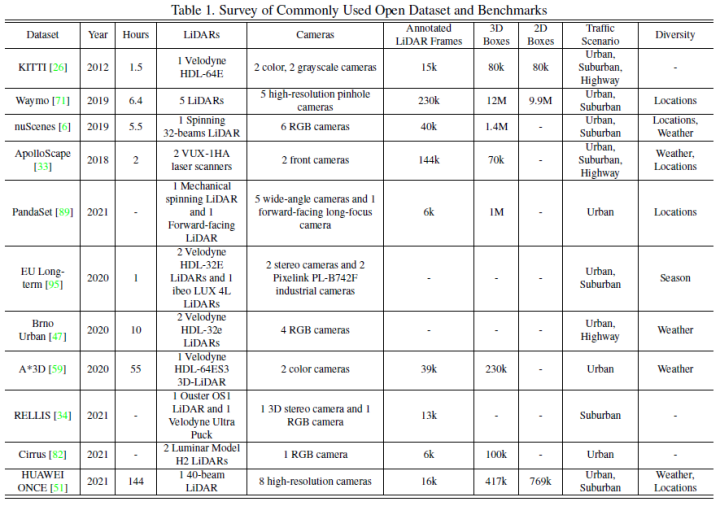
The commonly used open data sets mainly include Kitti, Waymo, and Nuscenes. The figure below summarizes the data sets and its characteristics related to autonomous driving perception.
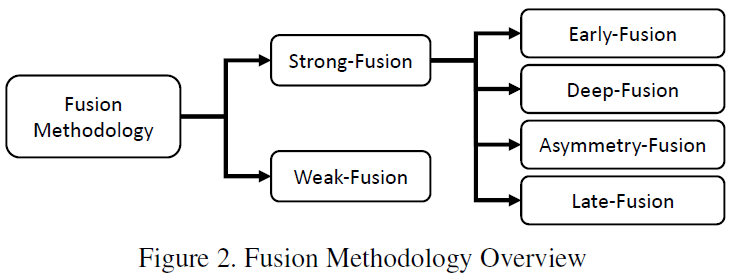
4 fusion method
Multi -mode fusion is inseparable from the form of data expression. The data of the image branch is relatively simple. Generally, it refers to the RGB format or gray graphics. The downstream model design includes three major directions: point cloud based on points, virgin and two -dimensional mapping.
Traditional classification methods are divided into the following three types:
Pre -fusion (data -level fusion) refers to the original sensor data that directly fuses different modes through space alignment.
In -depth fusion (characteristic level fusion) refers to cross -modular data multiplied by class federation or elements in feature space.
Later fusion (target -level integration) refers to the fusion of the prediction results of the model models and make final decisions.
This article uses the classification method below, which is divided into strong fusion and if fusion, and the strong fusion further segment is: front fusion, deep fusion, asymmetric fusion, and post -fusion.
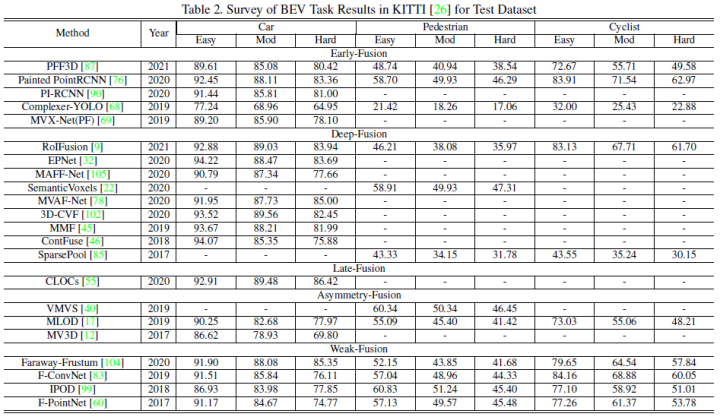
This article uses the performance of Kitti's 3D detection task and the BEV detection task horizontally to compare the performance of each multi -mode fusion algorithm. The following figure is the result of the BEV detection test set:
The figure below is the result of the 3D test test set:
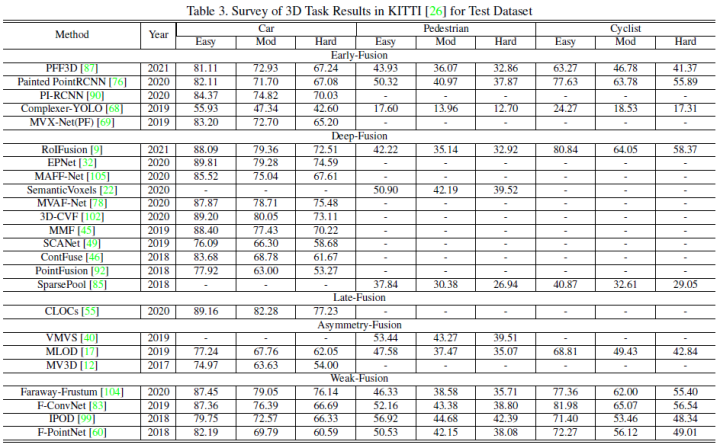
5th fusion
According to the different combination stages of laser radar and camera data, this article will be integrated into: front fusion, deep fusion, asymmetric fusion, and post -fusion. As shown in the figure above, it can be seen that each sub -module with strong fusion depends on the laser radar point cloud, not the camera data.
Front fusion
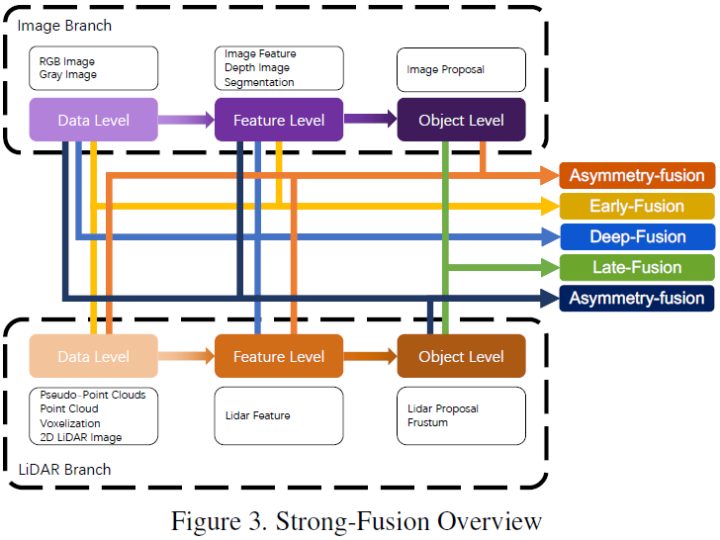
Unlike traditional data -level fusion definitions, the latter is a method that directly integrates each modal data through space alignment and projection at the original data level. Essence An example of early integration can be a model in Figure 4.
Unlike the pre -fusion of the definition of traditional classification methods, the pre -fusion defined in this article refers to the method that directly integrates various modular data through space alignment and projection at the original data level. Grade or feature -level fusion image data, the schematic diagram is as follows:
In the LIDAR branch, point clouds have a variety of expression forms, such as reflex maps, virtual tensor, front view/distance view/bev view, and pseudo -point cloud. Although these data have different internal features in combination with different main trunk networks, except for the pseudo -point cloud [79], most data are treated by certain rules. In addition, compared to the embedded feature space, these data of lidar are very explained and can be directly visual. In image branches, data -level definitions in strict sense should be RGB or gray graphics, but this definition lacks generality and rationality. Therefore, this article expands the data -level definition of image data in the previous fusion stage, including data -level and feature -level data. It is worth mentioning that this article also uses the results of semantic segmentation prediction as a kind of pre -fusion (image feature level). One is because it is conducive to 3D target detection, and the other is because of the "target level" characteristics of semantic segmentation and the final task of the entire task. The target -level proposal is different.
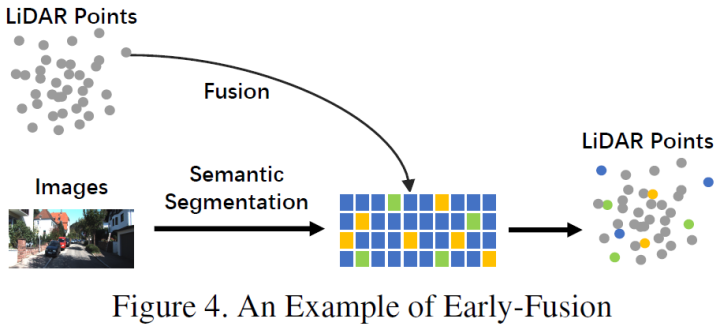
Deep fusion
In -depth fusion, also known as feature -level fusion, refers to the characteristic level of multi -modal data in the characteristic grade of laser radar branches, but the data set and characteristic level of the image branch are fused. For example, some methods use the features to raise the embedded representation of lidar point cloud and images, respectively, and use a series of downstream modules to integrate the characteristics of two modes [32, 102]. However, unlike other strong integration, deep fusion sometimes uses a level -based fusion feature [4, 32, 46], both of which use primitive and advanced semantic information. The schematic diagram is as follows:
Fusion
After the fusion, it can also be called the target -level fusion, which refers to the fusion of the prediction results (or proposal) of multiple modes. For example, some post -fusion methods use lidar point clouds and the output of images to integrate [55]. The data format of the PROPOSAL of the two branches should be consistent with the final result, but there are certain differences in quality, quantity and accuracy. After the fusion, it can be regarded as a multi -mode information optimization method of the final proposal. The schematic diagram is shown below:
Asymmetric fusion
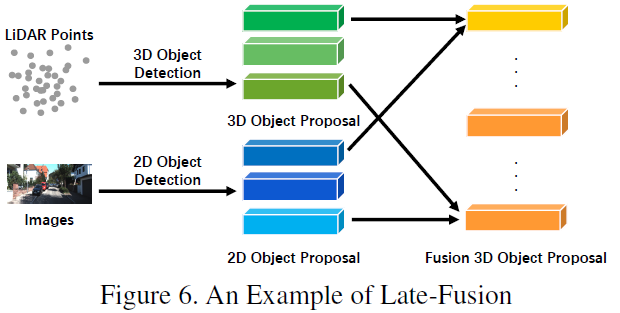
The last one of the strong fusion is asymmetric fusion, which refers to the target -level information of a branch and the data level or feature -level information of other branches. The above three fusion methods treat each branch of multi -mode, and asymmetric fusion emphasizes that at least one branch occupies a dominant position, and other branches provide the final result of assistance information prediction. The figure below is a schematic diagram of asymmetric fusion. In the PROPOSAL stage, the asymmetric fusion has only one branch of the proposal, and then the fusion is the proposal of all branches.
6 weak fusion
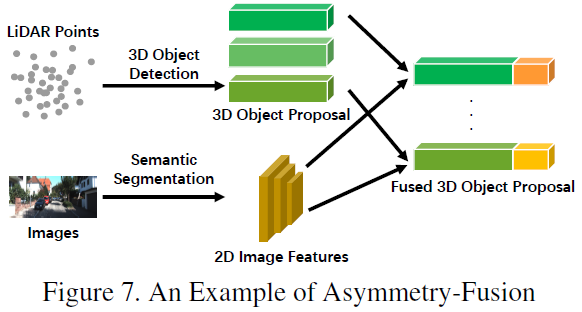
The difference with strong integration is that the weak fusion method does not fuse data, features or goals directly from multi -mode branches, but process data in other forms. The figure below shows the basic framework of the weak fusion algorithm. Based on weak fusion methods, a method based on a certain rule is used to use a modular data as a supervision signal to guide another modal interaction. For example, the 2D Proposal from CNN in the image branch may cause cutting off in the original Lidar dot cloud, and the weak fusion directly inputs the original Lidar point cloud into the Lidar trunk to output the final proposal [60].
7 Other ways fusion
There are also some jobs that do not belong to any of the above paradigms, because they use a variety of fusion methods in the framework of model design, such as [39] combined with deep integration and post -fusion, [77] combined with front fusion. These methods are not the mainstream methods of fusion algorithm design. This article is uniformly attributed to other fusion methods.
8 Opportunities for multimodal integration
In recent years, the multi -mode fusion method for autonomous driving perception tasks has made rapid progress. From more advanced features to more complex deep learning models [15, 81]. However, there are still some unreasonable issues to be resolved. This article summarizes the following possible improvements.
More advanced fusion method
The current fusion model has the problem of misplaced and information loss [13,67,98]. In addition, Flat Fusion operation [20, 76] also hindered the further improvement of perceived task performance. Summarized as follows:
Misplax and information loss: The internal and external differences between the camera and the lidar are very different, and the data of the two modes need to be aligned. The traditional pre -fusion and deep fusion method uses calibration information to directly project all lidar points to the camera coordinate system, and vice versa [54,69,76]. However, due to the position and sensor noise, the alignment of pixels is not accurate. Therefore, some work [90] uses surrounding information to supplement to obtain better performance. In addition, there are still some other information loss during the conversion of input and feature space. Generally, the projection of the dimension reduction operation will inevitably lead to a large amount of information loss. For example, the 3D Lidar point cloud mapping is lost in the 2D BEV image. Therefore, multi -mode data can be considered to be mapped to another high -dimensional space specially designed for integration, and then the original data can be effectively used to reduce information loss.
More reasonable integration operations: Many methods currently use the method of mobilizing levels or elements to integrate [69, 77]. These simple operations may not be able to fuse data with large differences in distribution, so it is difficult to fit the semantic red dogs between the two modes. Some work attempts to use a more complicated grade joint structure to integrate data and improve performance [12,46]. In future research, the mechanism of dual -line -based mapping [3,25,38] can integrate the characteristics of different characteristics, and it can also be considered. Utilization of multi -source information
Forest -based single -frame image is a typical scene of autonomous driving perception tasks [26]. However, most frameworks can only use limited information and do not design auxiliary tasks to promote the understanding of driving scenarios. Summarized as follows:
Use more potential information: the existing method [81] lacks effective use of information and source information. Most of them are energy on a single -frame multi -mode data in the forefront. This has caused other meaningful data to not be fully utilized, such as semantics, space, and scene context information. Some work [20, 76, 90] Try to use semantic segmentation results auxiliary tasks, while other models may use the intermediate features of the CNN trunk. In autonomous driving scenarios, many downstream tasks with explicit semantic information may greatly improve target detection performance, such as lane lines, traffic lights and traffic signs. Future research can combine downstream tasks to jointly build a complete semantic understanding framework for urban scene scenes to improve perceived performance. In addition, [63] combined with inter -frame information improvement performance. Time sequence information contains serialized monitoring signals. Compared with a single frame method, it can provide more stable results. Therefore, future work can be considered more in -depth time, context, and space information to achieve performance breakthrough.
Self -monitoring and learning: The signal of mutual supervision naturally exists in cross -modal data from the same real world scene but sampled at different angles. However, due to the lack of in -depth understanding of data, the current method cannot tap the relationship between various modes. Future research can focus on how to use multi -mode data for self -supervision and learning, including pre -training, fine -tuning or comparison learning. Through these advanced mechanisms, the fusion algorithm will deepen the model's deeper understanding of data and achieve better performance.
Sensor inherent problems
Domain deviation and resolution are related to the height of the scene and sensor in the real world [26]. These defects have hindered the large -scale training and real -time training of deep learning models of autonomous driving.
Domain deviation: In the scenario of autonomous driving perception, the original data extracted by different sensors accompanied by serious characteristics of the field. Different cameras have different optical characteristics, and LIDAR may be different from mechanical structure to solid structure. More importantly, the data itself will have domain deviations, such as weather, season or geographical location [6,71], even if it is captured by the same sensor. This has caused the generalization of the detection model to be affected and cannot effectively adapt to new scenes. Such defects have hindered the collection of large -scale data sets and reuse of original training data. Therefore, in the future, it can focus on finding a method of eliminating domain deviation and adapting to integrate different data sources.
Resolution conflict: Different sensors usually have different resolution [42, 100]. For example, the spatial density of lidar is significantly lower than the spatial density of the image. No matter which projection method is adopted, information losses will be caused because they cannot find the corresponding relationship. This may cause the model to be dominated by a specific modal data, whether it is the resolution of the feature vector or the imbalance of the original information. Therefore, future work can explore a new data compatible with different space resolution sensors.
9 reference
[1] https://zhuanlan.zhihu.com/p/470588787
[2] Multi-Modal Sensor Fusion for Auto Driving Perception: A Survey
Edit: Wang Jing
- END -
What?Does the chip still need to take a bath?

The following article comes from WeChat public account: fruit shell hard technolog...
Sun Heping: All human activities are closely related to gravity

In life, you will see the mature apples falling to the ground; in the ancient poem...